परिचय
 आर्टिफिशियल इंटेलिजेंस मशीनों का उपयोग करके लोगों के रोजमर्रा के जीवन को दिलचस्प और अनावश्यक कार्यों को सरल बनाकर उनके जीवन और जीवनशैली को ऊपर उठाने के बारे में है। एआई को कभी भी एक प्रभावशाली शक्ति नहीं माना जाता है, बल्कि एक पूरक शक्ति माना जाता है जो असंभव को हल करने और सामूहिक विकास का मार्ग प्रशस्त करने के लिए मनुष्यों के साथ मिलकर काम करता है।
आर्टिफिशियल इंटेलिजेंस मशीनों का उपयोग करके लोगों के रोजमर्रा के जीवन को दिलचस्प और अनावश्यक कार्यों को सरल बनाकर उनके जीवन और जीवनशैली को ऊपर उठाने के बारे में है। एआई को कभी भी एक प्रभावशाली शक्ति नहीं माना जाता है, बल्कि एक पूरक शक्ति माना जाता है जो असंभव को हल करने और सामूहिक विकास का मार्ग प्रशस्त करने के लिए मनुष्यों के साथ मिलकर काम करता है।
फिलहाल, हम एआई की मदद से उद्योगों में महत्वपूर्ण सफलताओं के साथ सही रास्ते पर चल रहे हैं। उदाहरण के लिए यदि आप स्वास्थ्य सेवा को लें, तो मशीन लर्निंग मॉडल के साथ एआई सिस्टम विशेषज्ञों को कैंसर को बेहतर ढंग से समझने और इसके उपचार के साथ आने में मदद कर रहा है। एआई की मदद से न्यूरोलॉजिकल विकारों और पीटीएसडी जैसी चिंताओं का इलाज किया जा रहा है। एआई-संचालित क्लिनिकल परीक्षणों और सिमुलेशन की बदौलत टीके तेजी से विकसित किए जा रहे हैं।
सिर्फ स्वास्थ्य सेवा ही नहीं, हर एक उद्योग या खंड जिसे एआई छूता है, उसमें क्रांतिकारी बदलाव आ रहा है। स्वायत्त वाहन, स्मार्ट सुविधा स्टोर, फिटबिट जैसे पहनने योग्य उपकरण और यहां तक कि हमारे स्मार्टफोन कैमरे एआई के साथ हमारे चेहरे की बेहतर तस्वीरें खींचने में सक्षम हैं।
एआई क्षेत्र में हो रहे नवाचारों की बदौलत, कंपनियां विभिन्न उपयोग के मामलों और समाधानों के साथ स्पेक्ट्रम में प्रवेश कर रही हैं। इसके कारण, वैश्विक AI बाजार के 267 के अंत तक लगभग $2027bn के बाजार मूल्य तक पहुंचने का अनुमान है। इसके अलावा, लगभग 37% व्यवसाय पहले से ही अपनी प्रक्रियाओं और उत्पादों में AI समाधान लागू कर रहे हैं।
अधिक दिलचस्प बात यह है कि आज हम जिन उत्पादों और सेवाओं का उपयोग करते हैं उनमें से लगभग 77% एआई द्वारा संचालित हैं। विभिन्न क्षेत्रों में तकनीकी अवधारणा के उल्लेखनीय रूप से बढ़ने के साथ, व्यवसाय एआई के साथ असंभव को कैसे प्रबंधित करते हैं?

 घड़ी जैसे सरल उपकरण मनुष्यों में दिल के दौरे की सटीक भविष्यवाणी कैसे करते हैं? यह कैसे संभव है कि जिन कारों और ऑटोमोबाइलों को हमेशा ड्राइवर की आवश्यकता होती है, अचानक सड़कों पर ड्राइवर कम हो जाएं?
घड़ी जैसे सरल उपकरण मनुष्यों में दिल के दौरे की सटीक भविष्यवाणी कैसे करते हैं? यह कैसे संभव है कि जिन कारों और ऑटोमोबाइलों को हमेशा ड्राइवर की आवश्यकता होती है, अचानक सड़कों पर ड्राइवर कम हो जाएं?
चैटबॉट हमें कैसे विश्वास दिलाते हैं कि हम दूसरी तरफ किसी अन्य इंसान से बात कर रहे हैं?
यदि आप प्रत्येक प्रश्न के उत्तर पर गौर करें, तो यह केवल एक तत्व - डेटा तक सीमित हो जाता है। डेटा सभी एआई-विशिष्ट संचालन और प्रक्रियाओं के केंद्र में है। यह डेटा है जो मशीनों को अवधारणाओं को समझने, इनपुट संसाधित करने और सटीक परिणाम देने में मदद करता है।
सभी प्रमुख एआई समाधान जो मौजूद हैं वे सभी एक महत्वपूर्ण प्रक्रिया के उत्पाद हैं जिन्हें हम डेटा संग्रह या डेटा अधिग्रहण या एआई प्रशिक्षण डेटा कहते हैं।
यह व्यापक मार्गदर्शिका आपको यह समझने में मदद करने के लिए है कि यह क्या है और यह महत्वपूर्ण क्यों है।
एआई डेटा संग्रह क्या है?
मशीनों के पास अपना कोई दिमाग नहीं होता. इस अमूर्त अवधारणा की अनुपस्थिति उन्हें राय, तथ्यों और तर्क, अनुभूति जैसी क्षमताओं से वंचित कर देती है। वे केवल अचल बक्से या जगह घेरने वाले उपकरण हैं। उन्हें शक्तिशाली माध्यमों में बदलने के लिए, आपको एल्गोरिदम और अधिक महत्वपूर्ण रूप से डेटा की आवश्यकता होती है।
 जो एल्गोरिदम विकसित किए गए हैं, उन्हें काम करने और संसाधित करने के लिए कुछ की आवश्यकता है और वह डेटा है जो प्रासंगिक, प्रासंगिक और हाल का है। मशीनों के लिए अपने इच्छित उद्देश्यों को पूरा करने के लिए ऐसे डेटा एकत्र करने की प्रक्रिया को एआई डेटा संग्रह कहा जाता है।
जो एल्गोरिदम विकसित किए गए हैं, उन्हें काम करने और संसाधित करने के लिए कुछ की आवश्यकता है और वह डेटा है जो प्रासंगिक, प्रासंगिक और हाल का है। मशीनों के लिए अपने इच्छित उद्देश्यों को पूरा करने के लिए ऐसे डेटा एकत्र करने की प्रक्रिया को एआई डेटा संग्रह कहा जाता है।
प्रत्येक एआई-सक्षम उत्पाद या समाधान जो हम आज उपयोग करते हैं और जो परिणाम वे प्रदान करते हैं वह वर्षों के प्रशिक्षण, विकास और अनुकूलन से आते हैं। उन उपकरणों से जो नेविगेशन मार्ग प्रदान करते हैं उन जटिल प्रणालियों तक जो उपकरण विफलता के दिनों की पहले से भविष्यवाणी करते हैं, हर एक इकाई को सटीक परिणाम देने में सक्षम होने के लिए वर्षों के एआई प्रशिक्षण से गुजरना पड़ा है।
एआई डेटा संग्रह एआई विकास की प्रक्रिया में प्रारंभिक चरण है जो शुरुआत से ही निर्धारित करता है कि एआई प्रणाली कितनी प्रभावी और कुशल होगी। यह असंख्य स्रोतों से प्रासंगिक डेटासेट को सोर्स करने की प्रक्रिया है जो एआई मॉडल को विवरण को बेहतर ढंग से संसाधित करने और सार्थक परिणाम निकालने में मदद करेगी।




मशीन लर्निंग के लिए डेटा कैसे एकत्रित करें?
 यहीं से चीजें थोड़ी मुश्किल होने लगती हैं। शुरू से ही, ऐसा प्रतीत होगा कि आपके दिमाग में वास्तविक दुनिया की किसी समस्या का समाधान है, आप जानते हैं कि एआई इसके लिए आदर्श तरीका होगा और आपने अपने मॉडल विकसित कर लिए हैं। लेकिन अब, आप महत्वपूर्ण चरण में हैं जहां आपको अपनी एआई प्रशिक्षण प्रक्रिया शुरू करने की आवश्यकता है। आपके मॉडलों को अवधारणाएँ सीखने और परिणाम देने के लिए आपके पास प्रचुर मात्रा में AI प्रशिक्षण डेटा की आवश्यकता है। आपको अपने परिणामों का परीक्षण करने और अपने एल्गोरिदम को अनुकूलित करने के लिए सत्यापन डेटा की भी आवश्यकता है।
यहीं से चीजें थोड़ी मुश्किल होने लगती हैं। शुरू से ही, ऐसा प्रतीत होगा कि आपके दिमाग में वास्तविक दुनिया की किसी समस्या का समाधान है, आप जानते हैं कि एआई इसके लिए आदर्श तरीका होगा और आपने अपने मॉडल विकसित कर लिए हैं। लेकिन अब, आप महत्वपूर्ण चरण में हैं जहां आपको अपनी एआई प्रशिक्षण प्रक्रिया शुरू करने की आवश्यकता है। आपके मॉडलों को अवधारणाएँ सीखने और परिणाम देने के लिए आपके पास प्रचुर मात्रा में AI प्रशिक्षण डेटा की आवश्यकता है। आपको अपने परिणामों का परीक्षण करने और अपने एल्गोरिदम को अनुकूलित करने के लिए सत्यापन डेटा की भी आवश्यकता है।
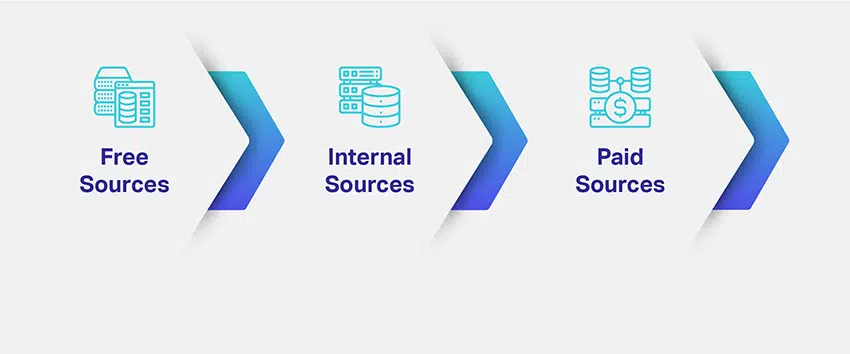
तो, आप अपना डेटा कैसे स्रोत करते हैं? आपको किस डेटा की आवश्यकता है और इसकी कितनी मात्रा है? प्रासंगिक डेटा लाने के लिए एकाधिक स्रोत क्या हैं?
कंपनियां अपने एमएल मॉडल के स्थान और उद्देश्य का आकलन करती हैं और प्रासंगिक डेटासेट प्राप्त करने के संभावित तरीकों का पता लगाती हैं। आवश्यक डेटा प्रकार को परिभाषित करने से डेटा सोर्सिंग पर आपकी चिंता का एक बड़ा हिस्सा हल हो जाता है। आपको बेहतर जानकारी देने के लिए, डेटा संग्रह के लिए विभिन्न चैनल, रास्ते, स्रोत या माध्यम हैं:
ख़राब डेटा आपकी AI महत्वाकांक्षाओं को कैसे प्रभावित करता है?
हमने तीन सबसे आम डेटा संसाधनों को सूचीबद्ध किया है ताकि आपको यह पता चल सके कि डेटा संग्रह और सोर्सिंग कैसे करें। हालाँकि, इस बिंदु पर, यह समझना भी आवश्यक हो जाता है कि आपका निर्णय निश्चित रूप से आपके एआई समाधान का भाग्य तय कर सकता है।
जिस तरह उच्च गुणवत्ता वाला एआई प्रशिक्षण डेटा आपके मॉडल को सटीक और समय पर परिणाम देने में मदद कर सकता है, उसी तरह खराब प्रशिक्षण डेटा भी आपके एआई मॉडल को तोड़ सकता है, परिणामों में गड़बड़ी कर सकता है, पूर्वाग्रह पैदा कर सकता है और अन्य अवांछनीय परिणाम पेश कर सकता है।
लेकिन ऐसा क्यों होता है? क्या कोई डेटा आपके AI मॉडल को प्रशिक्षित और अनुकूलित करने वाला नहीं है? ईमानदारी से नहीं। आइये इसे आगे समझते हैं.
ख़राब डेटा - यह क्या है?
 खराब डेटा कोई भी डेटा है जो अप्रासंगिक, गलत, अधूरा या पक्षपाती है। खराब परिभाषित डेटा संग्रह रणनीतियों के लिए धन्यवाद, अधिकांश डेटा वैज्ञानिक और एनोटेशन विशेषज्ञ खराब डेटा पर काम करने के लिए मजबूर हैं।
खराब डेटा कोई भी डेटा है जो अप्रासंगिक, गलत, अधूरा या पक्षपाती है। खराब परिभाषित डेटा संग्रह रणनीतियों के लिए धन्यवाद, अधिकांश डेटा वैज्ञानिक और एनोटेशन विशेषज्ञ खराब डेटा पर काम करने के लिए मजबूर हैं।
असंरचित और ख़राब डेटा के बीच अंतर यह है कि असंरचित डेटा में अंतर्दृष्टि हर जगह होती है। लेकिन संक्षेप में, वे बिना किसी परवाह के उपयोगी हो सकते हैं। अतिरिक्त समय खर्च करके, डेटा वैज्ञानिक अभी भी असंरचित डेटासेट से प्रासंगिक जानकारी निकालने में सक्षम होंगे। हालाँकि, ख़राब डेटा के मामले में ऐसा नहीं है। इन डेटासेट में कोई/सीमित अंतर्दृष्टि या जानकारी नहीं है जो आपके एआई प्रोजेक्ट या इसके प्रशिक्षण उद्देश्यों के लिए मूल्यवान या प्रासंगिक है।
इसलिए, जब आप अपने डेटासेट को मुफ़्त संसाधनों से प्राप्त करते हैं या आपके पास शिथिल रूप से स्थापित आंतरिक डेटा टच पॉइंट हैं, तो संभावना बहुत अधिक है कि आप खराब डेटा डाउनलोड करेंगे या उत्पन्न करेंगे। जब आपके वैज्ञानिक खराब डेटा पर काम करते हैं, तो आप न केवल मानव घंटे बर्बाद कर रहे हैं बल्कि अपने उत्पाद के लॉन्च को भी आगे बढ़ा रहे हैं।
यदि आप अभी भी इस बारे में स्पष्ट नहीं हैं कि ख़राब डेटा आपकी महत्वाकांक्षाओं पर क्या प्रभाव डाल सकता है, तो यहां एक त्वरित सूची दी गई है:
- आप ख़राब डेटा की सोर्सिंग में अनगिनत घंटे बिताते हैं और संसाधनों पर घंटों, प्रयास और पैसा बर्बाद करते हैं।
- यदि ध्यान न दिया गया तो खराब डेटा आपके लिए कानूनी परेशानियां खड़ी कर सकता है और आपके एआई की दक्षता को कम कर सकता है
मॉडल । - जब आप अपने उत्पाद को खराब डेटा पर लाइव प्रशिक्षित करते हैं, तो यह उपयोगकर्ता अनुभव को प्रभावित करता है
- ख़राब डेटा परिणामों और निष्कर्षों को पक्षपातपूर्ण बना सकता है, जिससे आगे चलकर प्रतिक्रियाएँ आ सकती हैं।
तो, यदि आप सोच रहे हैं कि क्या इसका कोई समाधान है, तो वास्तव में है।
एआई प्रशिक्षण डेटा प्रदाता बचाव के लिए
 बुनियादी समाधानों में से एक डेटा विक्रेता (भुगतान किए गए स्रोत) के लिए जाना है। एआई प्रशिक्षण डेटा प्रदाता यह सुनिश्चित करते हैं कि आपको जो प्राप्त होता है वह सटीक और प्रासंगिक है और आपके पास संरचित रूप में डेटासेट वितरित किए जाते हैं। आपको डेटासेट की तलाश में एक पोर्टल से दूसरे पोर्टल पर जाने की झंझट में शामिल होने की ज़रूरत नहीं है।
बुनियादी समाधानों में से एक डेटा विक्रेता (भुगतान किए गए स्रोत) के लिए जाना है। एआई प्रशिक्षण डेटा प्रदाता यह सुनिश्चित करते हैं कि आपको जो प्राप्त होता है वह सटीक और प्रासंगिक है और आपके पास संरचित रूप में डेटासेट वितरित किए जाते हैं। आपको डेटासेट की तलाश में एक पोर्टल से दूसरे पोर्टल पर जाने की झंझट में शामिल होने की ज़रूरत नहीं है।
आपको बस डेटा लेना है और अपने एआई मॉडल को पूर्णता के लिए प्रशिक्षित करना है। इसके साथ ही, हमें यकीन है कि आपका अगला प्रश्न डेटा विक्रेताओं के साथ सहयोग में आने वाले खर्चों पर है। हम समझते हैं कि आप में से कुछ लोग पहले से ही मानसिक बजट पर काम कर रहे हैं और हम आगे भी इसी ओर जा रहे हैं।
आपके डेटा संग्रहण प्रोजेक्ट के लिए प्रभावी बजट बनाते समय विचार करने योग्य कारक
एआई प्रशिक्षण एक व्यवस्थित दृष्टिकोण है और इसीलिए बजट बनाना इसका एक अभिन्न अंग बन जाता है। एआई विकास में भारी मात्रा में पैसा निवेश करने से पहले आरओआई, परिणामों की सटीकता, प्रशिक्षण पद्धतियां और बहुत कुछ जैसे कारकों पर विचार किया जाना चाहिए। बहुत से परियोजना प्रबंधक या व्यवसाय स्वामी इस स्तर पर गड़बड़ी करते हैं। वे जल्दबाजी में निर्णय लेते हैं जो उनकी उत्पाद विकास प्रक्रिया में अपरिवर्तनीय परिवर्तन लाते हैं, अंततः उन्हें अधिक खर्च करने के लिए मजबूर करते हैं।
हालाँकि, यह अनुभाग आपको सही जानकारी देगा। जब आप एआई प्रशिक्षण के लिए बजट पर काम करने के लिए बैठे हैं, तो तीन चीजें या कारक अपरिहार्य हैं।

आइए प्रत्येक को विस्तार से देखें।
आपके लिए आवश्यक डेटा की मात्रा
हम हमेशा से कहते रहे हैं कि आपके एआई मॉडल की दक्षता और सटीकता इस बात पर निर्भर करती है कि इसे कितना प्रशिक्षित किया गया है। इसका मतलब यह है कि डेटासेट की मात्रा जितनी अधिक होगी, सीखना उतना ही अधिक होगा। लेकिन यह बहुत अस्पष्ट है. इस धारणा को स्पष्ट करने के लिए, डायमेंशनल रिसर्च ने एक रिपोर्ट प्रकाशित की जिसमें पता चला कि व्यवसायों को अपने एआई मॉडल को प्रशिक्षित करने के लिए न्यूनतम 100,000 नमूना डेटासेट की आवश्यकता होती है।
100,000 डेटासेट से हमारा तात्पर्य 100,000 गुणवत्ता और प्रासंगिक डेटासेट से है। इन डेटासेट में जानकारी को संसाधित करने और इच्छित कार्यों को निष्पादित करने के लिए आपके एल्गोरिदम और मशीन लर्निंग मॉडल के लिए आवश्यक सभी आवश्यक विशेषताएं, एनोटेशन और अंतर्दृष्टि होनी चाहिए।
यह एक सामान्य नियम है, आइए आगे समझें कि आपके लिए आवश्यक डेटा की मात्रा एक अन्य जटिल कारक पर भी निर्भर करती है जो कि आपके व्यवसाय का उपयोग मामला है। आप अपने उत्पाद या समाधान के साथ क्या करना चाहते हैं यह भी तय करता है कि आपको कितने डेटा की आवश्यकता है। उदाहरण के लिए, अनुशंसा इंजन बनाने वाले व्यवसाय के लिए चैटबॉट बनाने वाली कंपनी की तुलना में डेटा वॉल्यूम की अलग-अलग आवश्यकताएं होंगी।
डेटा मूल्य निर्धारण रणनीति
जब आप यह तय कर लें कि आपको वास्तव में कितने डेटा की आवश्यकता है, तो आपको डेटा मूल्य निर्धारण रणनीति पर अगला काम करना होगा। सरल शब्दों में इसका मतलब है कि आप अपने द्वारा खरीदे या तैयार किए गए डेटासेट के लिए भुगतान कैसे करेंगे।
सामान्य तौर पर, ये बाजार में अपनाई जाने वाली पारंपरिक मूल्य निर्धारण रणनीतियाँ हैं:
| डाटा प्रकार | कीमत निर्धारण कार्यनीति |
|---|---|
| प्रति एकल छवि फ़ाइल का मूल्य | |
| प्रति सेकंड, मिनट, एक घंटा या व्यक्तिगत फ्रेम की कीमत | |
| प्रति सेकंड, एक मिनट या घंटे की कीमत | |
| प्रति शब्द या वाक्य का मूल्य |
पर रुको। यह फिर से एक सामान्य नियम है. डेटासेट खरीदने की वास्तविक लागत भी कारकों पर निर्भर करती है जैसे:
- अद्वितीय बाज़ार खंड, जनसांख्यिकी या भूगोल जहां से डेटासेट प्राप्त करना होता है
- आपके उपयोग के मामले की जटिलता
- आपको कितना डेटा चाहिए?
- बाजार जाने का आपका समय
- कोई अनुरूप आवश्यकताएँ और भी बहुत कुछ
यदि आप ध्यान दें, तो आपको पता चलेगा कि आपके एआई प्रोजेक्ट के लिए बड़ी मात्रा में छवियां प्राप्त करने की लागत कम हो सकती है, लेकिन यदि आपके पास बहुत अधिक विशिष्टताएं हैं, तो कीमतें बढ़ सकती हैं।
आपकी सोर्सिंग रणनीतियाँ
यह पेचीदा है. जैसा कि आपने देखा, आपके एआई मॉडल के लिए डेटा उत्पन्न करने या स्रोत करने के विभिन्न तरीके हैं। सामान्य ज्ञान यह निर्देशित करेगा कि मुफ़्त संसाधन सर्वोत्तम हैं क्योंकि आप बिना किसी जटिलता के आवश्यक मात्रा में डेटासेट मुफ्त में डाउनलोड कर सकते हैं।
फिलहाल, ऐसा भी प्रतीत होगा कि भुगतान किए गए स्रोत बहुत महंगे हैं। लेकिन यहीं पर जटिलता की एक परत जुड़ जाती है। जब आप मुफ़्त संसाधनों से डेटासेट प्राप्त कर रहे हैं, तो आप अपने डेटासेट को साफ़ करने, उन्हें अपने व्यवसाय-विशिष्ट प्रारूप में संकलित करने और फिर उन्हें व्यक्तिगत रूप से एनोटेट करने में अतिरिक्त समय और प्रयास खर्च कर रहे हैं। आप इस प्रक्रिया में परिचालन लागत खर्च कर रहे हैं।
भुगतान किए गए स्रोतों के साथ, भुगतान एकमुश्त होता है और आपको आवश्यक समय पर मशीन-तैयार डेटासेट भी मिल जाता है। यहां लागत-प्रभावशीलता बहुत व्यक्तिपरक है। यदि आपको लगता है कि आप मुफ़्त डेटासेट पर टिप्पणी करने में समय व्यतीत कर सकते हैं, तो आप तदनुसार बजट बना सकते हैं। और यदि आप मानते हैं कि आपकी प्रतिस्पर्धा भयंकर है और बाजार में सीमित समय के साथ, आप बाजार में एक लहर पैदा कर सकते हैं, तो आपको भुगतान किए गए स्रोतों को प्राथमिकता देनी चाहिए।
बजटिंग विशिष्टताओं को तोड़ने और प्रत्येक टुकड़े को स्पष्ट रूप से परिभाषित करने के बारे में है। इन तीन कारकों को भविष्य में आपके एआई प्रशिक्षण बजट प्रक्रिया के लिए एक रोडमैप के रूप में काम करना चाहिए।
क्या आप इन-हाउस डेटा अधिग्रहण के साथ खर्चों पर बचत कर रहे हैं?
 बजट बनाते समय, हमने पता लगाया कि कैसे मुफ़्त संसाधन आपको लंबी अवधि में अधिक खर्च करने के लिए मजबूर करते हैं। उस समय, आप स्वतः ही इन-हाउस डेटा अधिग्रहण प्रक्रिया की लागत-प्रभावशीलता के बारे में आश्चर्यचकित हो गए होंगे।
बजट बनाते समय, हमने पता लगाया कि कैसे मुफ़्त संसाधन आपको लंबी अवधि में अधिक खर्च करने के लिए मजबूर करते हैं। उस समय, आप स्वतः ही इन-हाउस डेटा अधिग्रहण प्रक्रिया की लागत-प्रभावशीलता के बारे में आश्चर्यचकित हो गए होंगे।
हम जानते हैं कि आप अभी भी भुगतान किए गए स्रोतों के बारे में झिझक रहे हैं और इसीलिए यह अनुभाग इसके बारे में आपके संदेह को दूर करेगा और इन-हाउस डेटा उत्पादन में शामिल छिपी हुई लागतों पर प्रकाश डालेगा।
क्या इन-हाउस डेटा अधिग्रहण महंगा है?
हाँ यही है!
अब, यहाँ एक विस्तृत प्रतिक्रिया है। व्यय वह है जो आप खर्च करते हैं। मुफ़्त संसाधनों पर चर्चा करते समय, हमने खुलासा किया कि आप इस प्रक्रिया में पैसा, समय और प्रयास खर्च करते हैं। यह इन-हाउस डेटा अधिग्रहण पर भी लागू होता है।
 इस तथ्य के कारण कि आपके पास कस्टम-परिभाषित स्पर्श बिंदु या डेटा फ़नल हैं, इसका मतलब यह नहीं है कि आपके पास होगा मशीन तैयार डेटासेट अंततः। आपके द्वारा उत्पन्न किया जाने वाला डेटा अभी भी ज्यादातर कच्चा और असंरचित होगा। आपके पास एक ही स्थान पर आवश्यक सभी डेटा हो सकते हैं, लेकिन जो डेटा है वह सभी जगह होगा।
इस तथ्य के कारण कि आपके पास कस्टम-परिभाषित स्पर्श बिंदु या डेटा फ़नल हैं, इसका मतलब यह नहीं है कि आपके पास होगा मशीन तैयार डेटासेट अंततः। आपके द्वारा उत्पन्न किया जाने वाला डेटा अभी भी ज्यादातर कच्चा और असंरचित होगा। आपके पास एक ही स्थान पर आवश्यक सभी डेटा हो सकते हैं, लेकिन जो डेटा है वह सभी जगह होगा।
अंततः, आप अपने कर्मचारियों, डेटा वैज्ञानिकों, एनोटेटर्स, गुणवत्ता आश्वासन पेशेवरों और अन्य को भुगतान करने पर खर्च करेंगे। आप एनोटेशन टूल और के लिए सदस्यता पर भी खर्च करेंगे
सीएमएस, सीआरएम और अन्य बुनियादी ढांचे के खर्चों का रखरखाव।
इसके अलावा, डेटासेट में पूर्वाग्रह और सटीकता संबंधी चिंताएं होती हैं, जिन्हें आपको मैन्युअल रूप से हल करने की आवश्यकता होती है। और यदि आपकी एआई प्रशिक्षण डेटा टीम में कोई एट्रिशन समस्या है, तो आपको नए सदस्यों को भर्ती करने, उन्हें अपनी प्रक्रियाओं के लिए उन्मुख करने, उन्हें अपने टूल का उपयोग करने के लिए प्रशिक्षित करने आदि पर खर्च करना होगा।
आप अंततः अपनी कमाई से अधिक खर्च कर देंगे। एनोटेशन खर्च भी हैं. किसी भी समय, इन-हाउस डेटा के साथ काम करने में आने वाली कुल लागत है:
खर्च की गई लागत = एनोटेटर्स की संख्या * प्रति एनोटेटर लागत + प्लेटफ़ॉर्म लागत
यदि आपका एआई प्रशिक्षण कैलेंडर महीनों के लिए निर्धारित है, तो कल्पना करें कि आप लगातार कितना खर्च करेंगे। तो, क्या यह डेटा अधिग्रहण संबंधी चिंताओं का आदर्श समाधान है या कोई विकल्प है?
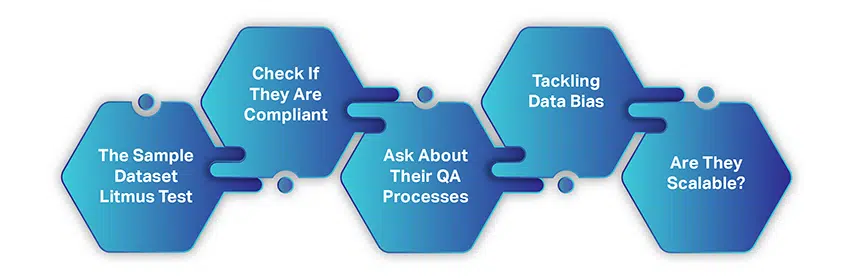
सही एआई डेटा संग्रहण कंपनी कैसे चुनें
एआई डेटा संग्रह कंपनी चुनना मुफ़्त संसाधनों से डेटा एकत्र करने जितना जटिल या समय लेने वाला नहीं है। केवल कुछ सरल कारक हैं जिन पर आपको विचार करना होगा और फिर सहयोग के लिए हाथ मिलाना होगा।
जब आप किसी डेटा विक्रेता की तलाश शुरू कर रहे हैं, तो हम मानते हैं कि आपने अब तक जो भी चर्चा की है उसका पालन किया है और उस पर विचार किया है। हालाँकि, यहाँ एक त्वरित पुनर्कथन है:
- आपके मन में एक सुपरिभाषित उपयोग मामला है
- आपका बाज़ार खंड और डेटा आवश्यकताएँ स्पष्ट रूप से स्थापित हैं
- आपका बजट सही है
- और आपको इस बात का अंदाज़ा है कि आपको कितने डेटा की आवश्यकता है
इन वस्तुओं की जांच के बाद, आइए समझें कि आप एक आदर्श प्रशिक्षण डेटा सेवा प्रदाता की तलाश कैसे कर सकते हैं।