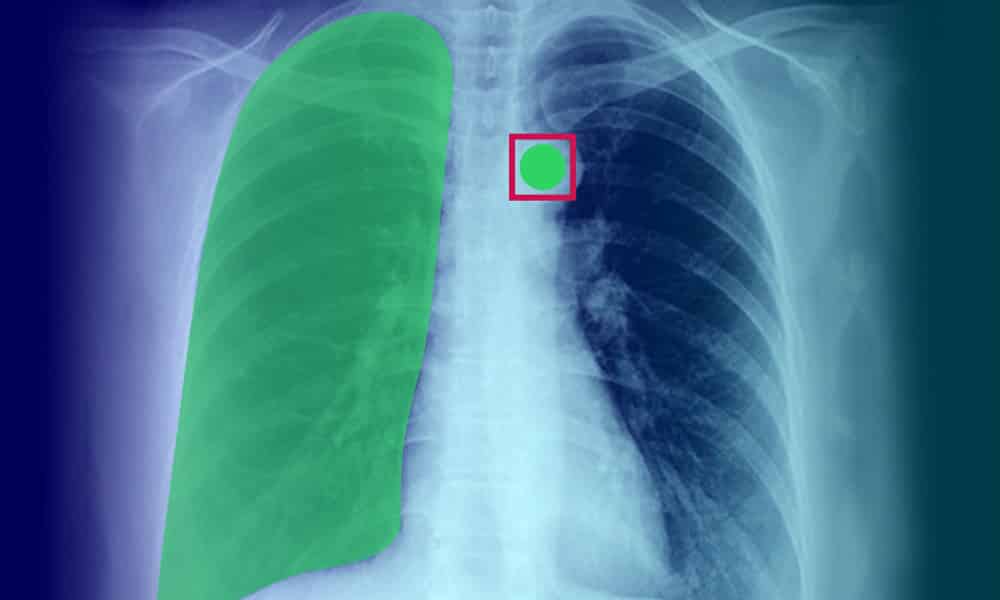
एक मजबूत एआई-आधारित समाधान डेटा पर बनाया गया है - न केवल कोई डेटा बल्कि उच्च-गुणवत्ता, सटीक रूप से एनोटेट डेटा। केवल सबसे अच्छा और सबसे परिष्कृत डेटा ही आपके AI प्रोजेक्ट को शक्ति प्रदान कर सकता है, और इस डेटा शुद्धता का प्रोजेक्ट के परिणाम पर बहुत बड़ा प्रभाव पड़ेगा।
हमने अक्सर एआई परियोजनाओं के लिए डेटा को ईंधन कहा है, लेकिन कोई भी डेटा काम नहीं करेगा। यदि आपको अपने प्रोजेक्ट को लिफ्टऑफ हासिल करने में मदद के लिए रॉकेट ईंधन की आवश्यकता है, तो आप टैंक में कच्चा तेल नहीं डाल सकते। इसके बजाय, डेटा (ईंधन की तरह) को यह सुनिश्चित करने के लिए सावधानीपूर्वक परिष्कृत करने की आवश्यकता है कि केवल उच्चतम-गुणवत्ता वाली जानकारी ही आपके प्रोजेक्ट को शक्ति प्रदान करे। उस परिशोधन प्रक्रिया को डेटा एनोटेशन कहा जाता है, और इसके बारे में काफी कुछ गलत धारणाएं मौजूद हैं।
एनोटेशन में प्रशिक्षण डेटा गुणवत्ता को परिभाषित करें
हम जानते हैं कि एआई परियोजना के परिणाम में डेटा गुणवत्ता का बहुत बड़ा अंतर है। कुछ बेहतरीन और सबसे उच्च प्रदर्शन वाले एमएल मॉडल विस्तृत और सटीक रूप से लेबल किए गए डेटासेट पर आधारित हैं।
लेकिन हम एनोटेशन में गुणवत्ता को वास्तव में कैसे परिभाषित करते हैं?
जब हम बात करते हैं डेटा एनोटेशन गुणवत्ता, सटीकता, विश्वसनीयता और निरंतरता मायने रखती है। एक डेटा सेट को सटीक कहा जाता है यदि यह जमीनी सच्चाई और वास्तविक दुनिया की जानकारी से मेल खाता हो।
डेटा की संगति पूरे डेटासेट में सटीकता के स्तर को बनाए रखने को संदर्भित करती है। हालांकि, डेटासेट की गुणवत्ता परियोजना के प्रकार, इसकी अनूठी आवश्यकताओं और वांछित परिणाम से अधिक सटीक रूप से निर्धारित होती है। इसलिए, डेटा लेबलिंग और एनोटेशन गुणवत्ता निर्धारित करने के लिए यह मानदंड होना चाहिए।
डेटा गुणवत्ता को परिभाषित करना क्यों महत्वपूर्ण है?
डेटा गुणवत्ता को परिभाषित करना महत्वपूर्ण है क्योंकि यह एक व्यापक कारक के रूप में कार्य करता है जो परियोजना की गुणवत्ता और परिणाम निर्धारित करता है।
- खराब गुणवत्ता डेटा उत्पाद और व्यावसायिक रणनीतियों को प्रभावित कर सकता है।
- एक मशीन लर्निंग सिस्टम उतना ही अच्छा होता है, जितनी उस डेटा की गुणवत्ता जिस पर उसे प्रशिक्षित किया जाता है।
- अच्छी गुणवत्ता वाला डेटा पुनः कार्य और उससे संबद्ध लागतों को समाप्त कर देता है।
- यह व्यवसायों को सूचित परियोजना निर्णय लेने में मदद करता है और नियामक अनुपालन का पालन करता है।
लेबलिंग करते समय हम प्रशिक्षण डेटा गुणवत्ता को कैसे मापते हैं?

प्रशिक्षण डेटा गुणवत्ता को मापने के लिए कई तरीके हैं, और उनमें से अधिकांश पहले ठोस डेटा एनोटेशन दिशानिर्देश बनाने के साथ शुरू होते हैं। कुछ विधियों में शामिल हैं:
विशेषज्ञों द्वारा स्थापित बेंचमार्क
गुणवत्ता बेंचमार्क या स्वर्ण मानक एनोटेशन तरीके सबसे आसान और सबसे किफायती गुणवत्ता आश्वासन विकल्प हैं जो एक संदर्भ बिंदु के रूप में काम करते हैं जो परियोजना की गुणवत्ता की गुणवत्ता को मापते हैं। यह विशेषज्ञों द्वारा स्थापित बेंचमार्क के विरुद्ध डेटा एनोटेशन को मापता है।
क्रोनबैक का अल्फा परीक्षण
क्रोनबैक का अल्फा टेस्ट डेटासेट आइटम्स के बीच सहसंबंध या स्थिरता को निर्धारित करता है। लेबल की विश्वसनीयता और अधिक सटीकता शोध के आधार पर मापा जा सकता है।
आम सहमति मापन
आम सहमति मापन मशीन या मानव एनोटेटर्स के बीच समझौते के स्तर को निर्धारित करता है। आम तौर पर प्रत्येक आइटम के लिए आम सहमति होनी चाहिए और असहमति के मामले में मध्यस्थता की जानी चाहिए।
पैनल समीक्षा
एक विशेषज्ञ पैनल आमतौर पर डेटा लेबल्स की समीक्षा करके लेबल की सटीकता निर्धारित करता है। कभी-कभी, सटीकता निर्धारित करने के लिए डेटा लेबल का एक परिभाषित भाग आमतौर पर एक नमूने के रूप में लिया जाता है।
की समीक्षा प्रशिक्षण जानकारी गुणवत्ता
एआई परियोजनाओं पर काम करने वाली कंपनियां पूरी तरह से स्वचालन की शक्ति में खरीदी जाती हैं, यही कारण है कि कई लोग सोचते रहते हैं कि एआई द्वारा संचालित ऑटो एनोटेशन मैन्युअल रूप से एनोटेट करने की तुलना में तेज़ और अधिक सटीक होगा। अभी के लिए, वास्तविकता यह है कि डेटा को पहचानने और वर्गीकृत करने के लिए मनुष्यों की आवश्यकता होती है क्योंकि सटीकता बहुत महत्वपूर्ण है। स्वचालित लेबलिंग के माध्यम से बनाई गई अतिरिक्त त्रुटियों को एल्गोरिदम की सटीकता में सुधार करने के लिए अतिरिक्त पुनरावृत्तियों की आवश्यकता होगी, जिससे किसी भी समय की बचत नहीं होगी।
एक और ग़लतफ़हमी - और जो संभवतः ऑटो एनोटेशन को अपनाने में योगदान दे रही है - वह यह है कि छोटी त्रुटियों का परिणामों पर अधिक प्रभाव नहीं पड़ता है। यहां तक कि एआई ड्रिफ्ट नामक घटना के कारण सबसे छोटी त्रुटियां भी महत्वपूर्ण अशुद्धियां उत्पन्न कर सकती हैं, जहां इनपुट डेटा में विसंगतियां एक एल्गोरिदम को उस दिशा में ले जाती हैं जो प्रोग्रामर ने कभी नहीं सोचा था।
परियोजनाओं की अनूठी मांगों को पूरा करने के लिए प्रशिक्षण डेटा की गुणवत्ता - सटीकता और स्थिरता के पहलुओं की लगातार समीक्षा की जाती है। प्रशिक्षण डेटा की समीक्षा आमतौर पर दो अलग-अलग तरीकों का उपयोग करके की जाती है -
ऑटो एनोटेट तकनीक
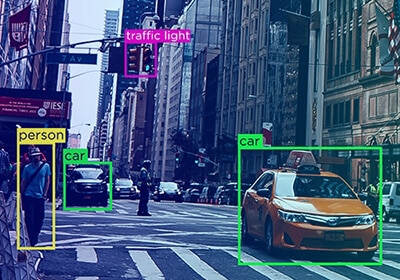 ऑटो एनोटेशन समीक्षा प्रक्रिया यह सुनिश्चित करती है कि फीडबैक को सिस्टम में वापस लूप किया जाता है और भ्रम को रोकता है ताकि एनोटेटर्स अपनी प्रक्रियाओं में सुधार कर सकें।
ऑटो एनोटेशन समीक्षा प्रक्रिया यह सुनिश्चित करती है कि फीडबैक को सिस्टम में वापस लूप किया जाता है और भ्रम को रोकता है ताकि एनोटेटर्स अपनी प्रक्रियाओं में सुधार कर सकें।
आर्टिफिशियल इंटेलिजेंस द्वारा संचालित ऑटो एनोटेशन सटीक और तेज है। ऑटो एनोटेशन समय मैनुअल QAs की समीक्षा में खर्च होने वाले समय को कम करता है, जिससे उन्हें डेटासेट में जटिल और महत्वपूर्ण त्रुटियों पर अधिक समय बिताने की अनुमति मिलती है। ऑटो एनोटेशन अमान्य उत्तरों, दोहराव और गलत एनोटेशन का पता लगाने में भी मदद कर सकता है।
डेटा विज्ञान विशेषज्ञों के माध्यम से मैन्युअल रूप से
डेटा वैज्ञानिक डेटासेट में सटीकता और विश्वसनीयता सुनिश्चित करने के लिए डेटा एनोटेशन की भी समीक्षा करते हैं।
छोटी त्रुटियां और एनोटेशन अशुद्धियां परियोजना के परिणाम को महत्वपूर्ण रूप से प्रभावित कर सकती हैं। और हो सकता है कि ऑटो एनोटेशन समीक्षा टूल द्वारा इन त्रुटियों का पता न लगाया जा सके। डेटा वैज्ञानिक डेटासेट में डेटा विसंगतियों और अनपेक्षित त्रुटियों का पता लगाने के लिए विभिन्न बैच आकार से नमूना गुणवत्ता परीक्षण करते हैं।
प्रत्येक एआई हेडलाइन के पीछे एक एनोटेशन प्रक्रिया होती है, और शेप इसे दर्द रहित बनाने में मदद कर सकता है
एआई प्रोजेक्ट के नुकसान से बचना
कई संगठन इन-हाउस एनोटेशन संसाधनों की कमी से त्रस्त हैं। डेटा वैज्ञानिक और इंजीनियर उच्च मांग में हैं, और एआई प्रोजेक्ट लेने के लिए इनमें से पर्याप्त पेशेवरों को काम पर रखने का मतलब है एक चेक लिखना जो ज्यादातर कंपनियों की पहुंच से बाहर है। एक बजट विकल्प (जैसे क्राउडसोर्सिंग एनोटेशन) चुनने के बजाय जो अंततः आपको परेशान करने के लिए वापस आ जाएगा, एक अनुभवी बाहरी साथी को अपनी एनोटेशन आवश्यकताओं को आउटसोर्स करने पर विचार करें। जब आप इन-हाउस टीम को इकट्ठा करने का प्रयास करते हैं तो भर्ती, प्रशिक्षण और प्रबंधन की बाधाओं को कम करते हुए आउटसोर्सिंग उच्च स्तर की सटीकता सुनिश्चित करती है।
जब आप विशेष रूप से शेप के साथ अपनी एनोटेशन आवश्यकताओं को आउटसोर्स करते हैं, तो आप एक शक्तिशाली ताकत में टैप करते हैं जो शॉर्टकट के बिना आपकी एआई पहल को तेज कर सकती है जो सभी महत्वपूर्ण परिणामों से समझौता करेगी। हम पूरी तरह से प्रबंधित कार्यबल की पेशकश करते हैं, जिसका अर्थ है कि आप क्राउडसोर्सिंग एनोटेशन प्रयासों से प्राप्त की तुलना में कहीं अधिक सटीकता प्राप्त कर सकते हैं। अग्रिम निवेश अधिक हो सकता है, लेकिन विकास प्रक्रिया के दौरान इसका लाभ मिलेगा जब वांछित परिणाम प्राप्त करने के लिए कम पुनरावृत्तियों की आवश्यकता होगी।
हमारी डेटा सेवाएँ सोर्सिंग सहित पूरी प्रक्रिया को कवर करती हैं, जो एक ऐसी क्षमता है जिसे अधिकांश अन्य लेबलिंग प्रदाता पेश नहीं कर सकते हैं। हमारे अनुभव से, आप बड़ी मात्रा में उच्च-गुणवत्ता, भौगोलिक दृष्टि से विविध डेटा जल्दी और आसानी से प्राप्त कर सकते हैं, जिसकी पहचान नहीं की गई है और जो सभी प्रासंगिक नियमों के अनुरूप है। जब आप इस डेटा को हमारे क्लाउड-आधारित प्लेटफ़ॉर्म में रखते हैं, तो आपको सिद्ध टूल और वर्कफ़्लो तक भी पहुंच मिलती है जो आपके प्रोजेक्ट की समग्र दक्षता को बढ़ावा देती है और आपकी अपेक्षा से अधिक तेज़ी से प्रगति करने में आपकी सहायता करती है।
और अंत में, हमारा घरेलू उद्योग विशेषज्ञ अपनी अनूठी जरूरतों को समझें। चाहे आप चैटबॉट बना रहे हों या स्वास्थ्य देखभाल में सुधार के लिए चेहरे की पहचान तकनीक को लागू करने के लिए काम कर रहे हों, हम वहां रहे हैं और दिशानिर्देशों को विकसित करने में मदद कर सकते हैं जो यह सुनिश्चित करेंगे कि एनोटेशन प्रक्रिया आपके प्रोजेक्ट के लिए उल्लिखित लक्ष्यों को पूरा करे।
शेप में, हम एआई के नए युग को लेकर उत्साहित नहीं हैं। हम इसमें अविश्वसनीय तरीकों से मदद कर रहे हैं, और हमारे अनुभव ने हमें अनगिनत सफल परियोजनाओं को जमीन पर उतारने में मदद की है। यह देखने के लिए कि हम आपके स्वयं के कार्यान्वयन के लिए क्या कर सकते हैं, हमसे संपर्क करें डेमो का अनुरोध करें आज।