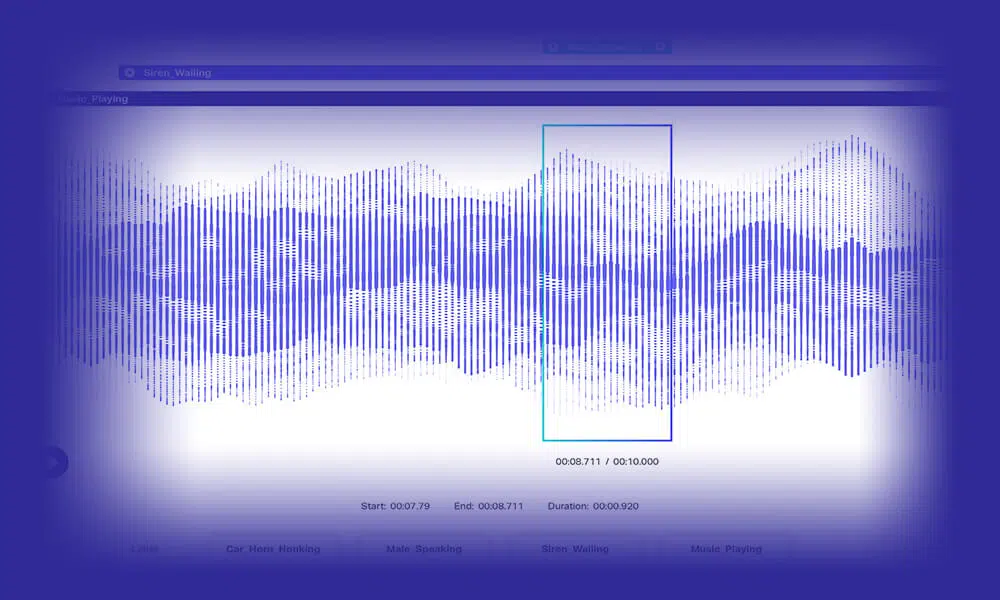


ऑडियो ट्रांसक्रिप्शन
सटीकता से लिखित भाषण/ऑडियो डेटा को ट्रक में भरकर बुद्धिमान एनएलपी मॉडल विकसित करें। शेप में, हम आपको मानक ऑडियो, शब्दशः और बहुभाषी ट्रांसक्रिप्शन सहित विकल्पों के व्यापक सेट में से चुनने देते हैं। साथ ही, आप अतिरिक्त स्पीकर पहचानकर्ताओं और टाइम-स्टैम्पिंग डेटा के साथ मॉडलों को प्रशिक्षित कर सकते हैं।
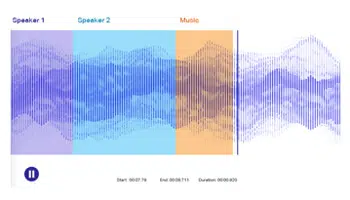
भाषण लेबलिंग
भाषण या ऑडियो लेबलिंग एक मानक एनोटेशन तकनीक है जो विशिष्ट मेटाडेटा के साथ ध्वनियों को अलग करने और लेबलिंग से संबंधित है। इस तकनीक के सार में ऑडियो के एक टुकड़े से ध्वनियों की ऑन्टोलॉजिकल पहचान और प्रशिक्षण डेटासेट को अधिक समावेशी बनाने के लिए उन्हें सटीक रूप से एनोटेट करना शामिल है।

ऑडियो वर्गीकरण
इसका उपयोग स्पीच एनोटेशन कंपनियों द्वारा एआई को पूर्णता के लिए प्रशिक्षित करने के लिए किया जाता है, सामग्री के अनुसार ऑडियो रिकॉर्डिंग का विश्लेषण करने से संबंधित है। ऑडियो वर्गीकरण के साथ, मशीनें आवाज़ों और ध्वनियों की पहचान कर सकती हैं, साथ ही अधिक सक्रिय प्रशिक्षण व्यवस्था के एक भाग के रूप में, दोनों के बीच अंतर करने में सक्षम हो सकती हैं।

बहुभाषी ऑडियो डेटा सेवाएँ
बहुभाषी ऑडियो डेटा एकत्र करना तभी उपयोगी है जब एनोटेटर उन्हें तदनुसार लेबल और विभाजित कर सकें। यह वह जगह है जहां बहुभाषी ऑडियो डेटा सेवाएं काम में आती हैं क्योंकि वे भाषा की विविधता के आधार पर भाषण को एनोटेट करने से संबंधित हैं, जिसे प्रासंगिक एआई द्वारा पूरी तरह से पहचाना और पार्स किया जाता है।

प्राकृतिक भाषा
कथन
एनएलयू अर्थ विज्ञान, बोलियाँ, संदर्भ, तनाव और बहुत कुछ जैसे छोटे विवरणों को वर्गीकृत करने के लिए मानव भाषण की व्याख्या करता है। एनोटेटेड डेटा का यह रूप वर्चुअल असिस्टेंट और चैटबॉट्स को बेहतर प्रशिक्षण देने में उपयोगी है।
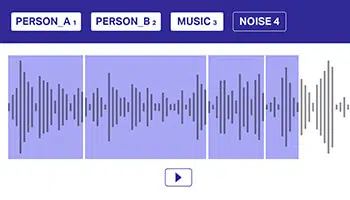
बहु लेबल
टिप्पणी
मॉडलों को ओवरलैपिंग ऑडियो स्रोतों को अलग करने में मदद करने के लिए एकाधिक लेबल का सहारा लेकर ऑडियो डेटा को एनोटेट करना महत्वपूर्ण है। इस दृष्टिकोण में, एक ऑडियो डेटासेट एक या कई वर्गों से संबंधित हो सकता है, जिसे बेहतर निर्णय लेने के लिए मॉडल को स्पष्ट रूप से बताने की आवश्यकता होती है।

स्पीकर डायराइजेशन
इसमें एक इनपुट ऑडियो फ़ाइल को अलग-अलग वक्ताओं से जुड़े समरूप खंडों में विभाजित करना शामिल है। डायराइजेशन का अर्थ है स्पीकर की सीमाओं की पहचान करना और अलग-अलग स्पीकरों की संख्या निर्धारित करने के लिए ऑडियो फाइलों को सेगमेंट में बांटना। यह प्रक्रिया कॉल सेंटर संवादों, चिकित्सा और कानूनी वार्तालापों और बैठकों के वार्तालाप विश्लेषण और लिप्यंतरण को स्वचालित करने में मदद करती है।

ध्वन्यात्मक प्रतिलेखन
नियमित ट्रांसक्रिप्शन के विपरीत जो ऑडियो को शब्दों के अनुक्रम में परिवर्तित करता है, ध्वन्यात्मक ट्रांसक्रिप्शन नोट करता है कि शब्दों का उच्चारण कैसे किया जाता है और ध्वन्यात्मक प्रतीकों का उपयोग करके ध्वनि का प्रतिनिधित्व करता है। ध्वन्यात्मक प्रतिलेखन कई बोलियों में एक ही भाषा के उच्चारण में अंतर को नोट करना आसान बनाता है।

स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा निर्माण, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम

प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप

मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण
स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा निर्माण, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम
प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप
मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण

पाठ एनोटेशन
सेवाएँ
हम इकाई एनोटेशन, टेक्स्ट वर्गीकरण, भावना एनोटेशन और अन्य प्रासंगिक टूल का उपयोग करके संपूर्ण डेटासेट को एनोटेट करके टेक्स्ट डेटा प्रशिक्षण तैयार करने में विशेषज्ञ हैं।

छवि एनोटेशन
सेवाएँ
हम कंप्यूटर विज़न मॉडल को प्रशिक्षित करने के लिए खंडित छवि डेटासेट को लेबल करने में गर्व महसूस करते हैं। कुछ प्रासंगिक तकनीकों में सीमा पहचान और छवि वर्गीकरण शामिल हैं।

वीडियो एनोटेशन
सेवाएँ
शेप कंप्यूटर विज़न मॉडल के प्रशिक्षण के लिए उच्च-स्तरीय वीडियो लेबलिंग सेवाएँ प्रदान करता है। इसका उद्देश्य डेटासेट को पैटर्न पहचान, ऑब्जेक्ट डिटेक्शन आदि जैसे उपकरणों के साथ प्रयोग करने योग्य बनाना है।


