

पाठ वर्गीकरण
पाठ एनोटेशन से संबंधित सबसे प्राथमिक दृष्टिकोण, जो सामग्री प्रकार, इरादे, भावना और विषय के आधार पर पाठ को वर्गीकृत करने पर केंद्रित है। एक बार वर्गीकृत होने के बाद, डेटासेट को पूर्वनिर्धारित खंड के एक भाग के रूप में सिस्टम में फीड किया जाता है, जिसे मशीनें प्रतिक्रिया उत्पन्न करने के लिए एक्सेस कर सकती हैं

भाषाई व्याख्या
मूल रूप से कॉर्पस एनोटेशन कहा जाता है, टेक्स्टुअल डेटासेट लेबलिंग का यह रूप ऑडियो और टेक्स्ट के भाषा विवरण पर केंद्रित है; साथ ही, इसमें ध्वन्यात्मक एनोटेशन, सिमेंटिक एनोटेशन के बिट्स, पीओएस टैगिंग आदि की भी आवश्यकता होती है। जब मशीनी अनुवाद मॉडल के प्रशिक्षण की बात आती है तो यह दृष्टिकोण प्रासंगिक होता है।

इकाई एनोटेशन
जब चैटबॉट प्रशिक्षण की बात आती है तो लेबलिंग की यह विधि महत्वपूर्ण है। यहां फोकस सिस्टम में डेटा फीड करने से पहले इकाइयों को निकालने, पता लगाने और टैग करने पर है। किसी भी चैटबॉट-संचालित इंटरफ़ेस की तरह, नाम इकाइयां, मुख्य वाक्यांश और पीओएस जैसे विशेषण, क्रियाविशेषण और बहुत कुछ केंद्रबिंदु बन जाते हैं।

इकाई लिंकिंग
जबकि एनोटेटर बड़े डेटा रिपॉजिटरी से इकाइयाँ निकालते हैं, उन्हें अर्थ रखने वाले डेटासेट बनाने के लिए आपस में जुड़ने की आवश्यकता होती है। यह कुछ टेक्स्ट एनोटेशन टूल में से एक है जिसमें असंबद्धता के माध्यम से संपूर्ण ज्ञान डेटाबेस स्थापित करना और अंततः एंड-टू-एंड लिंकिंग शामिल है। उदाहरण के लिए, यूआरएल रूटिंग, सीधे चैट इंटरफ़ेस से
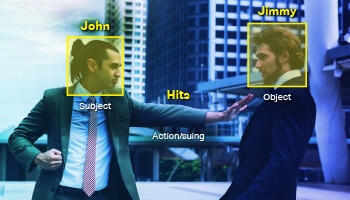
SAO (विषय क्रिया वस्तु)
जब किसी पाठ में एक क्रिया द्वारा जुड़े हुए अनेक निकाय होते हैं। उदाहरण के लिए, 'जॉन हिट्स जिमी', इकाई एनोटेशन और टेक्स्ट वर्गीकरण के लिए खुला है, जहां कानून-आधारित चर्चा से संबंधित एक लेबल जोड़ा जाता है। हालाँकि, मॉडल को वाक्य को समझने के लिए, उसे SAO डेटा फीड करने की आवश्यकता है, जिसमें जॉन विषय है, जिमी वस्तु है और मुकदमा कार्रवाई है।
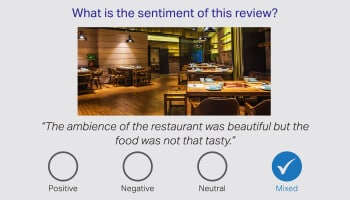
सेंटीमेंट एनोटेशन
सेंटीमेंट एनोटेशन भावनात्मक लेबलिंग का ख्याल रखता है और बुद्धिमान सेटअपों को छिपे हुए अर्थों, विचारों और विशिष्ट भावनाओं का पता लगाने की अनुमति देता है। व्याख्याकारों को पाठ की समीक्षा करने और उन्हें नकारात्मक, तटस्थ और सकारात्मक भावनाओं के रूप में लेबल करने की ज़िम्मेदारियाँ सौंपी जाती हैं। जबकि आशय एनोटेशन क्वेरी की इच्छा पर केंद्रित है।

स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा निर्माण, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम

प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप

मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण
स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा निर्माण, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम
प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप
मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण
ऑडियो एनोटेशन
सेवाएँ
स्पीच रिकग्निशन, स्पीकर डायराइजेशन, इमोशन रिकग्निशन और अधिक जैसे प्रासंगिक उपकरणों के माध्यम से ऑडियो स्रोतों, भाषण और आवाज-विशिष्ट डेटासेट को लेबल करना, कुछ ऐसा है जिसमें शेप माहिर है।

छवि एनोटेशन
सेवाएँ
हम समझदार कंप्यूटर विज़न मॉडल को प्रशिक्षित करने के लिए लेबलिंग, खंडित छवि डेटासेट में गर्व महसूस करते हैं। कुछ प्रासंगिक तकनीकों में सीमा पहचान और छवि वर्गीकरण शामिल हैं।

वीडियो एनोटेशन
सेवाएँ
शेप कंप्यूटर विज़न मॉडल के प्रशिक्षण के लिए उच्च-स्तरीय वीडियो लेबलिंग सेवाएँ प्रदान करता है। यहां उद्देश्य डेटासेट को पैटर्न पहचान, ऑब्जेक्ट डिटेक्शन और अन्य उपकरणों के साथ प्रयोग करने योग्य बनाना है।


