






पाठ संग्रह

ऑडियो/भाषण संग्रह
पाठ एनोटेशन
ऑडियो/भाषण एनोटेशन

पाठ प्रतिलेखन

ऑडियो/भाषण प्रतिलेखन




संवादात्मक एआई/चैटबॉट प्रशिक्षण
डिजिटल सहायकों को प्रशिक्षित करने के लिए विभिन्न भौगोलिक क्षेत्रों, भाषाओं, बोलियों, सेट-अप और प्रारूपों से गुणवत्ता वाले डेटा के एक बड़े सेट की आवश्यकता होती है। शेप में, हम ह्यूमन-इन-द-लूप वाले एआई मॉडल के लिए प्रशिक्षण डेटा प्रदान करते हैं जिनके पास आवश्यक ज्ञान, डोमेन विशेषज्ञता है, और ग्राहक की विशिष्ट आवश्यकताओं के बारे में अच्छी तरह से जानते हैं।
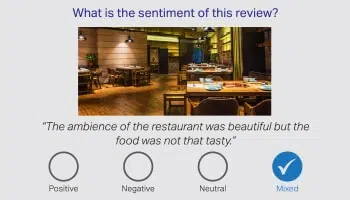
भाव/इरादा
विश्लेषण
यह ठीक ही कहा गया है, कि अकेले शब्द पूरी कहानी को संप्रेषित करने में विफल होते हैं, और मानव भाषा में अस्पष्टता की व्याख्या करने का दायित्व मानव व्याख्याकारों पर है। इसलिए बातचीत के आधार पर ग्राहक की भावना की पहचान करना अत्यंत महत्वपूर्ण है। विभिन्न क्षेत्रों के हमारे भाषा विशेषज्ञ उत्पाद समीक्षा, वित्तीय समाचार और सोशल मीडिया की बारीकियों की व्याख्या कर सकते हैं।

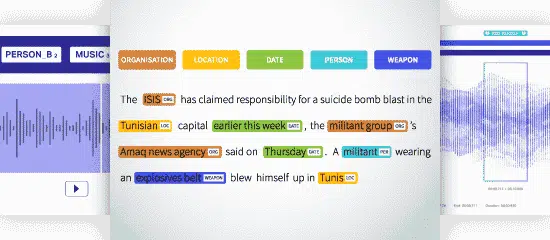
नामांकित मान्यता (एनईआर)
नामांकित इकाई पहचान (एनईआर) एक पाठ के भीतर नामित संस्थाओं को पूर्व-निर्धारित श्रेणियों में पहचानना, निकालना और वर्गीकृत करना है। पाठ को स्थान, नाम, संगठन, उत्पाद, मात्रा, मूल्य, प्रतिशत आदि के रूप में वर्गीकृत किया जा सकता है। एनईआर के साथ आप वास्तविक दुनिया के प्रश्नों को संबोधित कर सकते हैं जैसे कि लेख में किन संगठनों का उल्लेख किया गया था आदि।
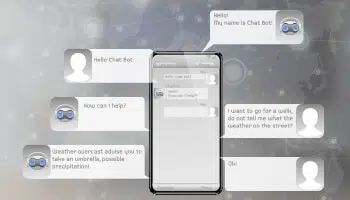
ग्राहक सेवा स्वचालन
मजबूत, अच्छी तरह से प्रशिक्षित वर्चुअल चैटबॉट्स या डिजिटल असिस्टेंट ने ग्राहकों के विक्रेताओं के साथ संवाद करने के तरीके में क्रांति ला दी है, जिससे ग्राहक अनुभव में महत्वपूर्ण सुधार हुआ है।

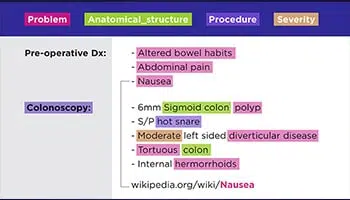
पाठ प्रतिलेखन
डॉक्टरों के हस्तलिखित नुस्खों से लेकर कॉन्फ़्रेंस कॉल नोट्स तक, हमारे विशेषज्ञ किसी भी प्रकार के डेटा यानी संग्रहीत दस्तावेज़, कानूनी अनुबंध, रोगी स्वास्थ्य रिकॉर्ड इत्यादि को डिजिटल कर सकते हैं।
सामग्री वर्गीकरण
वर्गीकरण को वर्गीकरण या टैगिंग के रूप में भी जाना जाता है, यह पाठ को संगठित समूहों में वर्गीकृत करने और उसकी रुचि की विशेषताओं के आधार पर लेबल करने की प्रक्रिया है।

विषय विश्लेषण
विषय विश्लेषण या विषय लेबलिंग, विचाराधीन आवर्ती विषयों/विषयों की पहचान करके किसी दिए गए पाठ से अर्थ निकालना है।

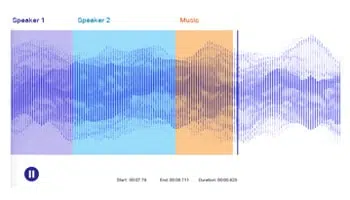
ऑडियो ट्रांसक्रिप्शन
भाषण/पॉडकास्ट/सेमिनार को ट्रांसक्राइब करें, बातचीत को टेक्स्ट में बदलें। एनएलपी मॉडल को सटीक रूप से प्रशिक्षित करने के लिए ऑडियो/भाषण फ़ाइलों को सटीक रूप से एनोटेट करने के लिए मनुष्यों का लाभ उठाएं।

ऑडियो वर्गीकरण
भाषा, बोली, शब्दार्थ, शब्दकोष आदि के आधार पर भाषण/ऑडियो को वर्गीकृत करने के लिए ध्वनियों या उच्चारणों को वर्गीकृत करें।

स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा निर्माण, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम

प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप

मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण


