



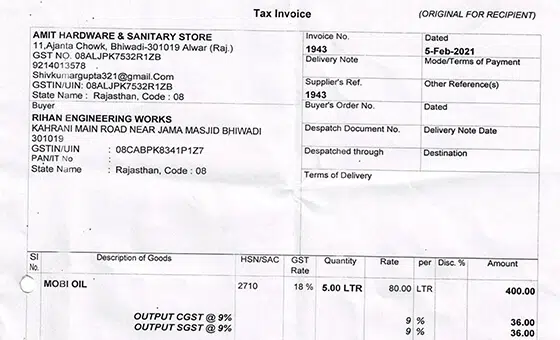






- उदाहरण: वस्तु पहचान मॉडल
- प्रारूप: वीडियो
- मात्रा: 5,000 +
- एनोटेशन: नहीं

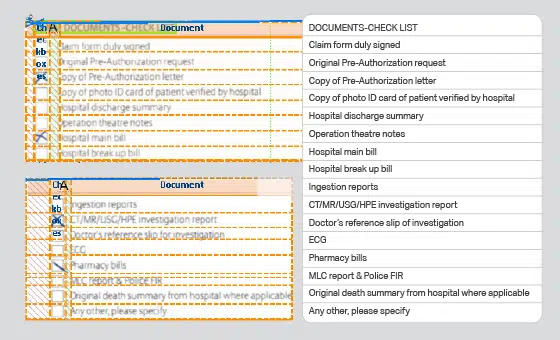
- उदाहरण: डॉक्टर। मान्यता मॉडल
- प्रारूप: छावियां
- मात्रा: 15,900 +
- एनोटेशन: नहीं
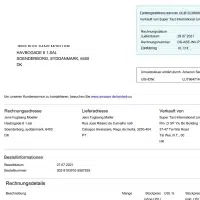
- उदाहरण: चालान पहचान। नमूना
- प्रारूप: छावियां
- मात्रा: 45,000 +
- एनोटेशन: नहीं

- उदाहरण: नंबर प्लेट पहचान
- प्रारूप: छावियां
- मात्रा: 3,500 +
- एनोटेशन: नहीं

- उदाहरण: ओसीआर मॉडल
- प्रारूप: छावियां
- मात्रा: 90,000 +
- एनोटेशन: हाँ

- उदाहरण: बहुभाषी ओसीआर मॉडल
- प्रारूप: छावियां
- मात्रा: 23,500 +
- एनोटेशन: हाँ
- उदाहरण: ऑब्जेक्ट डिटेक्शन मॉडल
- प्रारूप: छावियां
- मात्रा: 11,500 +
- एनोटेशन: नहीं

- उदाहरण: रसीद एआई मॉडल
- प्रारूप: छावियां
- मात्रा: 75,000 +
- एनोटेशन: नहीं

स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा संग्रह, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम

प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप

मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण



क्लिनिकल एनएलपी बनाना एक महत्वपूर्ण कार्य है जिसे हल करने के लिए जबरदस्त डोमेन विशेषज्ञता की आवश्यकता होती है। मैं स्पष्ट रूप से देख सकता हूं कि आप इस क्षेत्र में Google से कई वर्ष आगे हैं। मैं आपके साथ काम करना चाहता हूं और आपको स्केल करना चाहता हूं।
गूगल इंक। निदेशक
मेरी इंजीनियरिंग टीम ने हेल्थकेयर स्पीच एपीआई के विकास के दौरान 2+ वर्षों तक शैप की टीम के साथ काम किया। हम स्वास्थ्य देखभाल-विशिष्ट एनएलपी में किए गए उनके काम से प्रभावित हुए हैं और वे जटिल डेटासेट के साथ क्या हासिल करने में सक्षम हैं।
गूगल इंक। इंजीनियरिंग के प्रमुख