

बड़े भाषा मॉडल क्या हैं?
बड़े भाषा मॉडल (एलएलएम) उन्नत कृत्रिम बुद्धिमत्ता (एआई) सिस्टम हैं जिन्हें मानव-जैसे पाठ को संसाधित करने, समझने और उत्पन्न करने के लिए डिज़ाइन किया गया है। वे गहन शिक्षण तकनीकों पर आधारित हैं और बड़े पैमाने पर डेटासेट पर प्रशिक्षित हैं, जिनमें आमतौर पर वेबसाइटों, पुस्तकों और लेखों जैसे विभिन्न स्रोतों से अरबों शब्द शामिल होते हैं। यह व्यापक प्रशिक्षण एलएलएम को भाषा, व्याकरण, संदर्भ और यहां तक कि सामान्य ज्ञान के कुछ पहलुओं की बारीकियों को समझने में सक्षम बनाता है।
कुछ लोकप्रिय एलएलएम, जैसे ओपनएआई का जीपीटी-3, एक प्रकार के तंत्रिका नेटवर्क का उपयोग करते हैं जिसे ट्रांसफार्मर कहा जाता है, जो उन्हें उल्लेखनीय दक्षता के साथ जटिल भाषा कार्यों को संभालने की अनुमति देता है। ये मॉडल कई प्रकार के कार्य कर सकते हैं, जैसे:
- सवालों का जवाब दे
- पाठ का सारांश
- भाषाओं का अनुवाद करना
- सामग्री तैयार करना
- यहां तक कि उपयोगकर्ताओं के साथ इंटरैक्टिव बातचीत में भी शामिल होना
जैसे-जैसे एलएलएम का विकास जारी है, उनमें ग्राहक सेवा और सामग्री निर्माण से लेकर शिक्षा और अनुसंधान तक विभिन्न उद्योगों में विभिन्न अनुप्रयोगों को बढ़ाने और स्वचालित करने की काफी संभावनाएं हैं। हालाँकि, वे पक्षपातपूर्ण व्यवहार या दुरुपयोग जैसी नैतिक और सामाजिक चिंताओं को भी उठाते हैं, जिन्हें प्रौद्योगिकी प्रगति के रूप में संबोधित करने की आवश्यकता है।

बड़े भाषा मॉडल के लोकप्रिय उदाहरण
विभिन्न उद्योगों में व्यापक रूप से उपयोग किए जाने वाले एलएलएम के कुछ प्रमुख उदाहरण यहां दिए गए हैं:
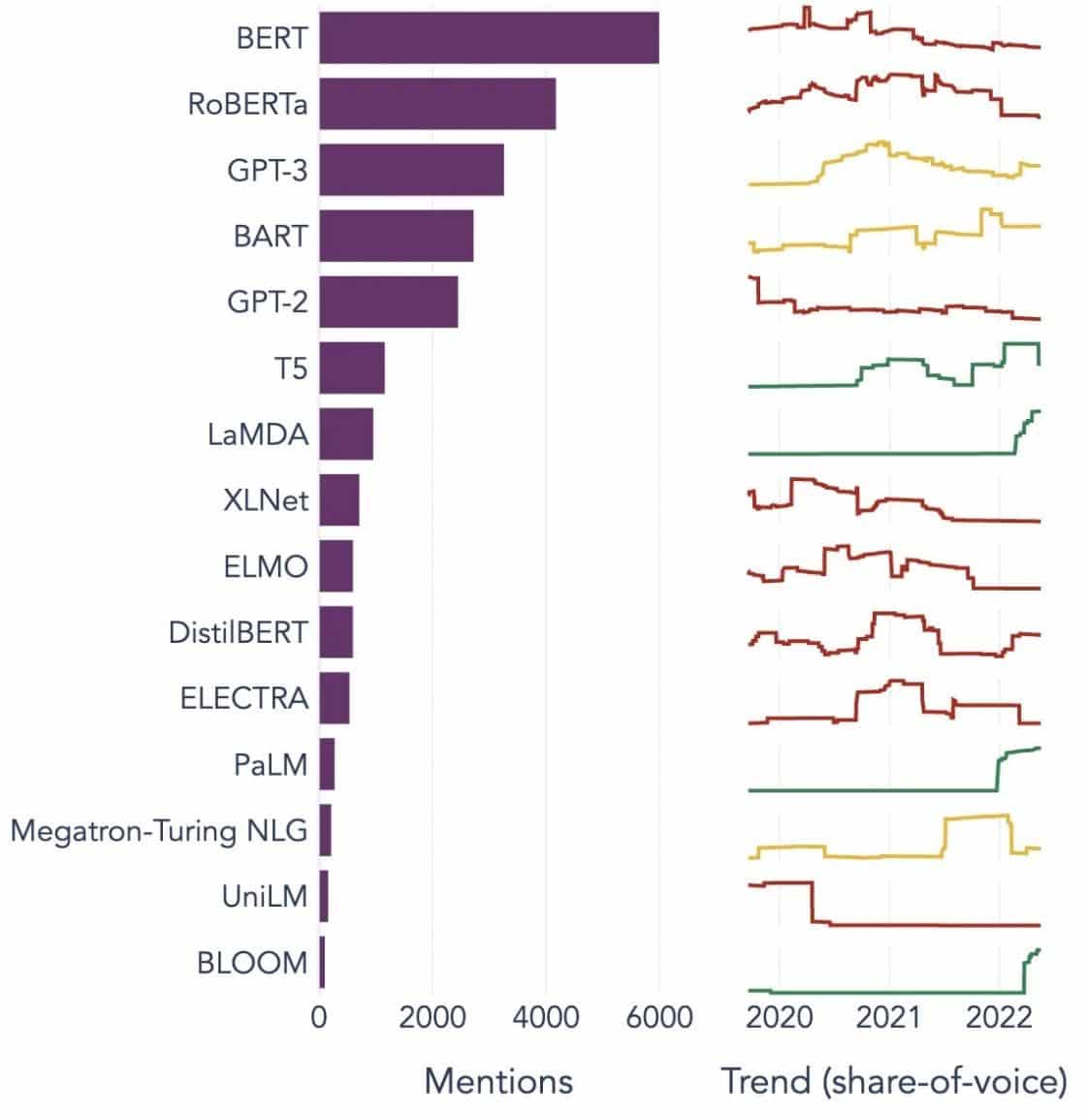
छवि स्रोत: डेटा साइंस की ओर
एलएलएम मॉडलों को कैसे प्रशिक्षित किया जाता है?
बड़े भाषा मॉडल (एलएलएम) का प्रशिक्षण एक बड़ी उपलब्धि है जिसमें कई महत्वपूर्ण चरण शामिल हैं। यहां प्रक्रिया का सरलीकृत, चरण-दर-चरण विवरण दिया गया है:
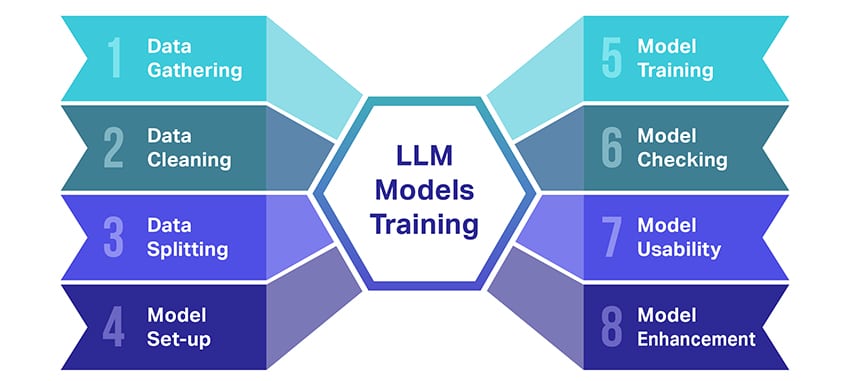
- पाठ डेटा एकत्रित करना: एलएलएम का प्रशिक्षण बड़ी मात्रा में टेक्स्ट डेटा के संग्रह से शुरू होता है। यह डेटा किताबों, वेबसाइटों, लेखों या सोशल मीडिया प्लेटफ़ॉर्म से आ सकता है। इसका उद्देश्य मानव भाषा की समृद्ध विविधता को पकड़ना है।
- डेटा साफ़ करना: फिर कच्चे टेक्स्ट डेटा को प्रीप्रोसेसिंग नामक प्रक्रिया में व्यवस्थित किया जाता है। इसमें अवांछित वर्णों को हटाना, पाठ को छोटे भागों में तोड़ना, जिन्हें टोकन कहा जाता है, और इन सभी को एक प्रारूप में लाना, जिसके साथ मॉडल काम कर सकता है, जैसे कार्य शामिल हैं।
- डेटा को विभाजित करना: इसके बाद, साफ़ डेटा को दो सेटों में विभाजित किया जाता है। मॉडल को प्रशिक्षित करने के लिए एक सेट, प्रशिक्षण डेटा का उपयोग किया जाएगा। अन्य सेट, सत्यापन डेटा, का उपयोग बाद में मॉडल के प्रदर्शन का परीक्षण करने के लिए किया जाएगा।
- मॉडल की स्थापना: एलएलएम की संरचना, जिसे वास्तुकला के रूप में जाना जाता है, को तब परिभाषित किया जाता है। इसमें तंत्रिका नेटवर्क के प्रकार का चयन करना और विभिन्न मापदंडों पर निर्णय लेना शामिल है, जैसे नेटवर्क के भीतर परतों और छिपी इकाइयों की संख्या।
- मॉडल का प्रशिक्षण: वास्तविक प्रशिक्षण अब शुरू होता है। एलएलएम मॉडल प्रशिक्षण डेटा को देखकर, अब तक जो सीखा है उसके आधार पर भविष्यवाणियां करके और फिर अपनी भविष्यवाणियों और वास्तविक डेटा के बीच अंतर को कम करने के लिए अपने आंतरिक मापदंडों को समायोजित करके सीखता है।
- मॉडल की जाँच करना: एलएलएम मॉडल की शिक्षा को सत्यापन डेटा का उपयोग करके जांचा जाता है। इससे यह देखने में मदद मिलती है कि मॉडल कितना अच्छा प्रदर्शन कर रहा है और बेहतर प्रदर्शन के लिए मॉडल की सेटिंग्स में बदलाव करता है।
- मॉडल का उपयोग करना: प्रशिक्षण और मूल्यांकन के बाद, एलएलएम मॉडल उपयोग के लिए तैयार है। इसे अब एप्लिकेशन या सिस्टम में एकीकृत किया जा सकता है जहां यह दिए गए नए इनपुट के आधार पर टेक्स्ट उत्पन्न करेगा।
- मॉडल में सुधार: अंततः, सुधार की गुंजाइश हमेशा रहती है। अद्यतन डेटा का उपयोग करके या फीडबैक और वास्तविक दुनिया के उपयोग के आधार पर सेटिंग्स को समायोजित करके एलएलएम मॉडल को समय के साथ और अधिक परिष्कृत किया जा सकता है।
याद रखें, इस प्रक्रिया के लिए महत्वपूर्ण कम्प्यूटेशनल संसाधनों की आवश्यकता होती है, जैसे शक्तिशाली प्रसंस्करण इकाइयाँ और बड़े भंडारण, साथ ही मशीन लर्निंग में विशेष ज्ञान। इसीलिए यह आमतौर पर समर्पित अनुसंधान संगठनों या आवश्यक बुनियादी ढांचे और विशेषज्ञता तक पहुंच वाली कंपनियों द्वारा किया जाता है।
क्या एलएलएम पर्यवेक्षित या अपर्यवेक्षित शिक्षण पर निर्भर है?
बड़े भाषा मॉडलों को आमतौर पर पर्यवेक्षित शिक्षण नामक विधि का उपयोग करके प्रशिक्षित किया जाता है। सरल शब्दों में, इसका मतलब है कि वे उन उदाहरणों से सीखते हैं जो उन्हें सही उत्तर दिखाते हैं।
 कल्पना कीजिए कि आप किसी बच्चे को चित्र दिखाकर शब्द सिखा रहे हैं। आप उन्हें बिल्ली की तस्वीर दिखाते हैं और कहते हैं "बिल्ली", और वे उस तस्वीर को शब्द के साथ जोड़ना सीखते हैं। पर्यवेक्षित शिक्षण इसी प्रकार काम करता है। मॉडल को बहुत सारे टेक्स्ट ("चित्र") और संबंधित आउटपुट ("शब्द") दिए जाते हैं, और यह उनका मिलान करना सीखता है।
कल्पना कीजिए कि आप किसी बच्चे को चित्र दिखाकर शब्द सिखा रहे हैं। आप उन्हें बिल्ली की तस्वीर दिखाते हैं और कहते हैं "बिल्ली", और वे उस तस्वीर को शब्द के साथ जोड़ना सीखते हैं। पर्यवेक्षित शिक्षण इसी प्रकार काम करता है। मॉडल को बहुत सारे टेक्स्ट ("चित्र") और संबंधित आउटपुट ("शब्द") दिए जाते हैं, और यह उनका मिलान करना सीखता है।
इसलिए, यदि आप एलएलएम को एक वाक्य देते हैं, तो यह उदाहरणों से जो सीखा है उसके आधार पर अगले शब्द या वाक्यांश की भविष्यवाणी करने की कोशिश करता है। इस तरह, यह सीखता है कि ऐसे पाठ को कैसे उत्पन्न किया जाए जो अर्थपूर्ण हो और संदर्भ के अनुकूल हो।
जैसा कि कहा गया है, कभी-कभी एलएलएम भी कुछ हद तक बिना पर्यवेक्षित शिक्षण का उपयोग करते हैं। यह बच्चे को विभिन्न खिलौनों से भरे कमरे का पता लगाने और उनके बारे में स्वयं सीखने देने जैसा है। मॉडल "सही" उत्तर बताए बिना बिना लेबल वाले डेटा, सीखने के पैटर्न और संरचनाओं को देखता है।
पर्यवेक्षित शिक्षण उस डेटा को नियोजित करता है जिसे इनपुट और आउटपुट के साथ लेबल किया गया है, गैर-पर्यवेक्षित शिक्षण के विपरीत, जो लेबल किए गए आउटपुट डेटा का उपयोग नहीं करता है।
संक्षेप में, एलएलएम को मुख्य रूप से पर्यवेक्षित शिक्षण का उपयोग करके प्रशिक्षित किया जाता है, लेकिन वे अपनी क्षमताओं को बढ़ाने के लिए, जैसे खोजपूर्ण विश्लेषण और आयामीता में कमी के लिए, बिना पर्यवेक्षित शिक्षण का भी उपयोग कर सकते हैं।
एक बड़े भाषा मॉडल को प्रशिक्षित करने के लिए आवश्यक डेटा वॉल्यूम (जीबी में) क्या है?
स्पीच डेटा रिकग्निशन और वॉइस एप्लिकेशन के लिए संभावनाओं की दुनिया बहुत बड़ी है, और इनका उपयोग कई उद्योगों में अनुप्रयोगों की अधिकता के लिए किया जा रहा है।
एक बड़े भाषा मॉडल को प्रशिक्षित करना सभी के लिए एक जैसी प्रक्रिया नहीं है, खासकर जब आवश्यक डेटा की बात आती है। यह बहुत सारी चीज़ों पर निर्भर करता है:
- मॉडल डिज़ाइन.
- इसे कौन सा कार्य करने की आवश्यकता है?
- आप जिस प्रकार का डेटा उपयोग कर रहे हैं.
- आप इसे कितना अच्छा प्रदर्शन करना चाहते हैं?
जैसा कि कहा गया है, एलएलएम के प्रशिक्षण के लिए आमतौर पर भारी मात्रा में टेक्स्ट डेटा की आवश्यकता होती है। लेकिन हम कितने बड़े पैमाने की बात कर रहे हैं? खैर, गीगाबाइट्स (जीबी) से आगे के बारे में सोचें। हम आमतौर पर टेराबाइट्स (टीबी) या यहां तक कि पेटाबाइट्स (पीबी) डेटा को देख रहे हैं।
सबसे बड़े एलएलएम में से एक, जीपीटी-3 पर विचार करें। इस पर प्रशिक्षण दिया जाता है 570 जीबी टेक्स्ट डेटा. छोटे एलएलएम को कम की आवश्यकता हो सकती है - शायद 10-20 जीबी या 1 जीबी गीगाबाइट - लेकिन यह अभी भी बहुत अधिक है।

लेकिन यह केवल डेटा के आकार के बारे में नहीं है। गुणवत्ता भी मायने रखती है. मॉडल को प्रभावी ढंग से सीखने में मदद करने के लिए डेटा को साफ और विविध होना चाहिए। और आप पहेली के अन्य प्रमुख हिस्सों के बारे में नहीं भूल सकते, जैसे कि आपके लिए आवश्यक कंप्यूटिंग शक्ति, प्रशिक्षण के लिए आपके द्वारा उपयोग किए जाने वाले एल्गोरिदम और आपके पास मौजूद हार्डवेयर सेटअप। ये सभी कारक एलएलएम के प्रशिक्षण में एक बड़ी भूमिका निभाते हैं।
बड़े भाषा मॉडल का उदय: वे क्यों मायने रखते हैं
एलएलएम अब केवल एक अवधारणा या प्रयोग नहीं रह गया है। वे हमारे डिजिटल परिदृश्य में तेजी से महत्वपूर्ण भूमिका निभा रहे हैं। लेकिन ऐसा क्यों हो रहा है? इन एलएलएम को इतना महत्वपूर्ण क्या बनाता है? आइए कुछ प्रमुख कारकों पर गौर करें।
मानव पाठ की नकल करने में महारत
एलएलएम ने भाषा-आधारित कार्यों को संभालने के हमारे तरीके को बदल दिया है। मजबूत मशीन लर्निंग एल्गोरिदम का उपयोग करके निर्मित, ये मॉडल कुछ हद तक संदर्भ, भावना और यहां तक कि व्यंग्य सहित मानव भाषा की बारीकियों को समझने की क्षमता से लैस हैं। मानव भाषा की नकल करने की यह क्षमता महज एक नवीनता नहीं है, इसके महत्वपूर्ण निहितार्थ हैं।
एलएलएम की उन्नत पाठ निर्माण क्षमताएं सामग्री निर्माण से लेकर ग्राहक सेवा इंटरैक्शन तक सब कुछ बढ़ा सकती हैं।
कल्पना कीजिए कि आप एक डिजिटल सहायक से एक जटिल प्रश्न पूछ सकते हैं और ऐसा उत्तर प्राप्त कर सकते हैं जो न केवल समझ में आता है, बल्कि सुसंगत, प्रासंगिक और बातचीत के लहजे में दिया गया है। एलएलएम यही सक्षम कर रहे हैं। वे अधिक सहज और आकर्षक मानव-मशीन संपर्क को बढ़ावा दे रहे हैं, उपयोगकर्ता अनुभवों को समृद्ध कर रहे हैं और सूचना तक पहुंच का लोकतंत्रीकरण कर रहे हैं।
किफायती कंप्यूटिंग पावर
कंप्यूटिंग के क्षेत्र में समानांतर विकास के बिना एलएलएम का उदय संभव नहीं होता। अधिक विशेष रूप से, कम्प्यूटेशनल संसाधनों के लोकतंत्रीकरण ने एलएलएम के विकास और अपनाने में महत्वपूर्ण भूमिका निभाई है।
क्लाउड-आधारित प्लेटफ़ॉर्म उच्च-प्रदर्शन कंप्यूटिंग संसाधनों तक अभूतपूर्व पहुंच प्रदान कर रहे हैं। इस तरह, छोटे पैमाने के संगठन और स्वतंत्र शोधकर्ता भी परिष्कृत मशीन लर्निंग मॉडल को प्रशिक्षित कर सकते हैं।
इसके अलावा, वितरित कंप्यूटिंग के उदय के साथ प्रसंस्करण इकाइयों (जैसे जीपीयू और टीपीयू) में सुधार ने अरबों मापदंडों के साथ मॉडल को प्रशिक्षित करना संभव बना दिया है। कंप्यूटिंग शक्ति की यह बढ़ी हुई पहुंच एलएलएम की वृद्धि और सफलता को सक्षम कर रही है, जिससे क्षेत्र में अधिक नवाचार और अनुप्रयोग हो रहे हैं।
उपभोक्ता प्राथमिकताएँ बदलना
आज उपभोक्ता केवल उत्तर ही नहीं चाहते; वे आकर्षक और प्रासंगिक बातचीत चाहते हैं। जैसे-जैसे अधिक लोग डिजिटल तकनीक का उपयोग कर रहे हैं, यह स्पष्ट है कि अधिक प्राकृतिक और मानवीय महसूस करने वाली तकनीक की आवश्यकता बढ़ रही है। एलएलएम इन अपेक्षाओं को पूरा करने के लिए एक बेजोड़ अवसर प्रदान करते हैं। मानव-जैसा पाठ उत्पन्न करके, ये मॉडल आकर्षक और गतिशील डिजिटल अनुभव बना सकते हैं, जो उपयोगकर्ता की संतुष्टि और वफादारी बढ़ा सकते हैं। चाहे वह ग्राहक सेवा प्रदान करने वाले एआई चैटबॉट हों या समाचार अपडेट प्रदान करने वाले वॉयस असिस्टेंट हों, एलएलएम एआई के युग की शुरुआत कर रहे हैं जो हमें बेहतर ढंग से समझता है।
असंरचित डेटा गोल्डमाइन
ईमेल, सोशल मीडिया पोस्ट और ग्राहक समीक्षा जैसे असंरचित डेटा, अंतर्दृष्टि का खजाना है। अनुमान है कि ख़त्म हो चुका है 80% तक एंटरप्राइज़ डेटा असंरचित है और की दर से बढ़ रहा है 55% तक प्रति वर्ष। यदि सही तरीके से उपयोग किया जाए तो यह डेटा व्यवसायों के लिए सोने की खान है।
बड़े पैमाने पर ऐसे डेटा को संसाधित करने और समझने की क्षमता के साथ, एलएलएम यहां काम में आते हैं। वे भावना विश्लेषण, पाठ वर्गीकरण, सूचना निष्कर्षण और बहुत कुछ जैसे कार्यों को संभाल सकते हैं, जिससे मूल्यवान अंतर्दृष्टि प्रदान की जा सकती है।
चाहे वह सोशल मीडिया पोस्ट से रुझानों की पहचान करना हो या समीक्षाओं से ग्राहकों की भावनाओं का आकलन करना हो, एलएलएम व्यवसायों को बड़ी मात्रा में असंरचित डेटा को नेविगेट करने और डेटा-संचालित निर्णय लेने में मदद कर रहे हैं।
विस्तारित एनएलपी बाज़ार
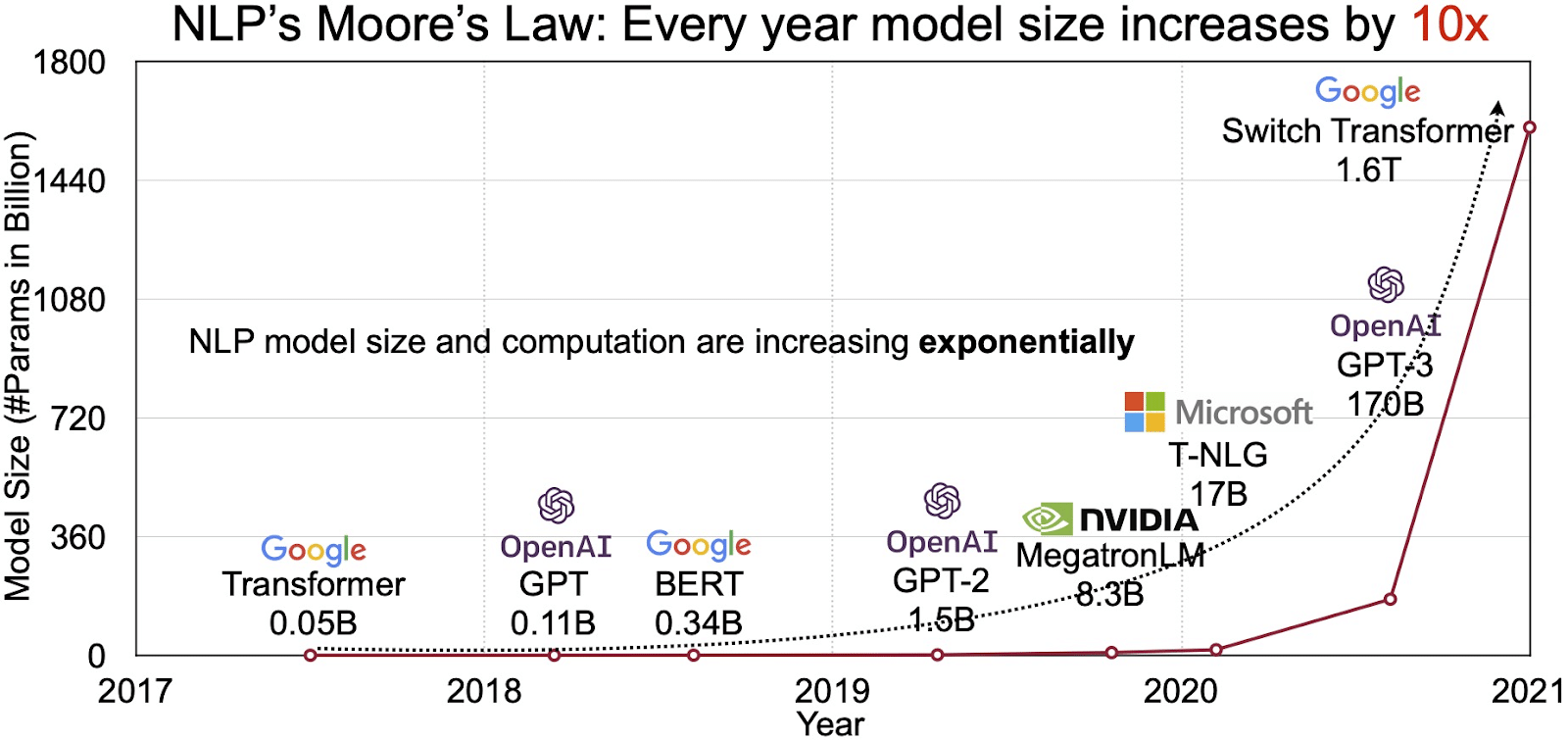
एलएलएम की क्षमता प्राकृतिक भाषा प्रसंस्करण (एनएलपी) के तेजी से बढ़ते बाजार में परिलक्षित होती है। विश्लेषकों का अनुमान है कि एनएलपी बाज़ार का विस्तार होगा 11 में $2020 बिलियन से 35 तक $2026 बिलियन से अधिक. लेकिन यह सिर्फ बाज़ार का आकार नहीं है जिसका विस्तार हो रहा है। मॉडल स्वयं भी बढ़ रहे हैं, भौतिक आकार और उनके द्वारा संभाले जाने वाले मापदंडों की संख्या दोनों में। पिछले कुछ वर्षों में एलएलएम का विकास, जैसा कि नीचे दिए गए चित्र (छवि स्रोत: लिंक) में देखा गया है, उनकी बढ़ती जटिलता और क्षमता को रेखांकित करता है।
बड़े भाषा मॉडल के लोकप्रिय उपयोग के मामले
एलएलएम के कुछ शीर्ष और सबसे प्रचलित उपयोग मामले यहां दिए गए हैं:
- प्राकृतिक भाषा पाठ उत्पन्न करना: बड़े भाषा मॉडल (एलएलएम) प्राकृतिक भाषा में स्वायत्त रूप से पाठ तैयार करने के लिए कृत्रिम बुद्धि और कम्प्यूटेशनल भाषाविज्ञान की शक्ति को जोड़ते हैं। वे उपयोगकर्ताओं की विविध आवश्यकताओं को पूरा कर सकते हैं जैसे कि लेख लिखना, गाने तैयार करना, या उपयोगकर्ताओं के साथ बातचीत में शामिल होना।
- मशीनों के माध्यम से अनुवाद: एलएलएम को किसी भी जोड़ी भाषाओं के बीच पाठ का अनुवाद करने के लिए प्रभावी ढंग से नियोजित किया जा सकता है। ये मॉडल स्रोत और लक्ष्य भाषाओं दोनों की भाषाई संरचना को समझने के लिए आवर्तक तंत्रिका नेटवर्क जैसे गहन शिक्षण एल्गोरिदम का उपयोग करते हैं, जिससे स्रोत पाठ का वांछित भाषा में अनुवाद करने में सुविधा होती है।
- मूल सामग्री तैयार करना: एलएलएम ने मशीनों के लिए सामंजस्यपूर्ण और तार्किक सामग्री उत्पन्न करने के रास्ते खोल दिए हैं। इस सामग्री का उपयोग ब्लॉग पोस्ट, लेख और अन्य प्रकार की सामग्री बनाने के लिए किया जा सकता है। मॉडल सामग्री को नए और उपयोगकर्ता के अनुकूल तरीके से प्रारूपित और संरचित करने के लिए अपने गहन सीखने के अनुभव का उपयोग करते हैं।
- भावनाओं का विश्लेषण: बड़े भाषा मॉडल का एक दिलचस्प अनुप्रयोग भावना विश्लेषण है। इसमें मॉडल को एनोटेट किए गए पाठ में मौजूद भावनात्मक स्थितियों और भावनाओं को पहचानने और वर्गीकृत करने के लिए प्रशिक्षित किया जाता है। सॉफ्टवेयर सकारात्मकता, नकारात्मकता, तटस्थता और अन्य जटिल भावनाओं जैसी भावनाओं की पहचान कर सकता है। यह विभिन्न उत्पादों और सेवाओं के बारे में ग्राहकों की प्रतिक्रिया और विचारों में मूल्यवान अंतर्दृष्टि प्रदान कर सकता है।
- पाठ को समझना, सारांशित करना और वर्गीकृत करना: एलएलएम पाठ और उसके संदर्भ की व्याख्या करने के लिए एआई सॉफ्टवेयर के लिए एक व्यवहार्य संरचना स्थापित करते हैं। मॉडल को विशाल मात्रा में डेटा को समझने और जांचने का निर्देश देकर, एलएलएम एआई मॉडल को पाठ को समझने, सारांशित करने और यहां तक कि विभिन्न रूपों और पैटर्न में वर्गीकृत करने में सक्षम बनाता है।
- सवालों का जवाब दे: बड़े भाषा मॉडल प्रश्न उत्तर (क्यूए) सिस्टम को उपयोगकर्ता की प्राकृतिक भाषा क्वेरी को सटीक रूप से समझने और उसका जवाब देने की क्षमता से लैस करते हैं। इस उपयोग के मामले के लोकप्रिय उदाहरणों में चैटजीपीटी और बीईआरटी शामिल हैं, जो एक क्वेरी के संदर्भ की जांच करते हैं और उपयोगकर्ता के सवालों के प्रासंगिक जवाब देने के लिए ग्रंथों के विशाल संग्रह के माध्यम से छान-बीन करते हैं।

पार्ट-ऑफ-स्पीच (पीओएस) टैगिंग
वाक्यों में शब्दों को उनके व्याकरणिक कार्य, जैसे क्रिया, संज्ञा, विशेषण आदि के साथ टैग किया जाता है। यह प्रक्रिया मॉडल को व्याकरण और शब्दों के बीच संबंधों को समझने में सहायता करती है।

नामांकित मान्यता (एनईआर)
एक वाक्य के भीतर संगठनों, स्थानों और लोगों जैसी नामित संस्थाओं को चिह्नित किया जाता है। यह अभ्यास मॉडल को शब्दों और वाक्यांशों के अर्थपूर्ण अर्थों की व्याख्या करने में सहायता करता है और अधिक सटीक प्रतिक्रियाएँ प्रदान करता है।

भावनाओं का विश्लेषण
टेक्स्ट डेटा को सकारात्मक, तटस्थ या नकारात्मक जैसे भावना लेबल दिए गए हैं, जिससे मॉडल को वाक्यों के भावनात्मक स्वर को समझने में मदद मिलती है। यह भावनाओं और विचारों से जुड़े प्रश्नों का उत्तर देने में विशेष रूप से उपयोगी है।
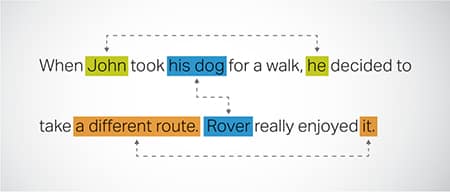
सहसंदर्भ संकल्प
ऐसे उदाहरणों की पहचान करना और उनका समाधान करना जहां पाठ के विभिन्न भागों में एक ही इकाई को संदर्भित किया जाता है। यह कदम मॉडल को वाक्य के संदर्भ को समझने में मदद करता है, जिससे सुसंगत प्रतिक्रियाएं मिलती हैं।
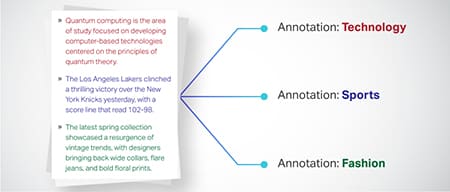
पाठ वर्गीकरण
टेक्स्ट डेटा को उत्पाद समीक्षा या समाचार लेख जैसे पूर्वनिर्धारित समूहों में वर्गीकृत किया गया है। यह मॉडल को पाठ की शैली या विषय को समझने, अधिक प्रासंगिक प्रतिक्रियाएँ उत्पन्न करने में सहायता करता है।
शेप की पेशकश
शेप देना संगठनों को अपने डेटा का प्रबंधन, विश्लेषण और अधिकतम उपयोग करने में मदद करने के लिए सेवाओं की एक विस्तृत श्रृंखला प्रदान करता है।
डेटा वेब-स्क्रैपिंग
शैप द्वारा दी जाने वाली एक प्रमुख सेवा डेटा स्क्रैपिंग है। इसमें डोमेन-विशिष्ट यूआरएल से डेटा निकालना शामिल है। स्वचालित उपकरणों और तकनीकों का उपयोग करके, शेप विभिन्न वेबसाइटों, उत्पाद मैनुअल, तकनीकी दस्तावेज़ीकरण, ऑनलाइन फ़ोरम, ऑनलाइन समीक्षा, ग्राहक सेवा डेटा, उद्योग नियामक दस्तावेज़ इत्यादि से बड़ी मात्रा में डेटा को तेज़ी से और कुशलतापूर्वक स्क्रैप कर सकता है। यह प्रक्रिया व्यवसायों के लिए अमूल्य हो सकती है जब अनेक स्रोतों से प्रासंगिक और विशिष्ट डेटा एकत्र करना।

यंत्र अनुवाद
विभिन्न भाषाओं में पाठ का अनुवाद करने के लिए संबंधित प्रतिलेखन के साथ जोड़े गए व्यापक बहुभाषी डेटासेट का उपयोग करके मॉडल विकसित करें। यह प्रक्रिया भाषाई बाधाओं को दूर करने में मदद करती है और सूचना की पहुंच को बढ़ावा देती है।
वर्गीकरण निष्कर्षण एवं निर्माण
शेप वर्गीकरण निष्कर्षण और निर्माण में मदद कर सकता है। इसमें डेटा को एक संरचित प्रारूप में वर्गीकृत और वर्गीकृत करना शामिल है जो विभिन्न डेटा बिंदुओं के बीच संबंधों को दर्शाता है। यह व्यवसायों के लिए अपने डेटा को व्यवस्थित करने में विशेष रूप से उपयोगी हो सकता है, जिससे इसे अधिक सुलभ और विश्लेषण करना आसान हो जाएगा। उदाहरण के लिए, ई-कॉमर्स व्यवसाय में, उत्पाद डेटा को उत्पाद प्रकार, ब्रांड, कीमत आदि के आधार पर वर्गीकृत किया जा सकता है, जिससे ग्राहकों के लिए उत्पाद कैटलॉग को नेविगेट करना आसान हो जाता है।
डेटा संग्रहण
हमारी डेटा संग्रह सेवाएँ जेनेरिक एआई एल्गोरिदम को प्रशिक्षित करने और आपके मॉडल की सटीकता और प्रभावशीलता में सुधार के लिए आवश्यक महत्वपूर्ण वास्तविक दुनिया या सिंथेटिक डेटा प्रदान करती हैं। डेटा गोपनीयता और सुरक्षा को ध्यान में रखते हुए डेटा निष्पक्ष, नैतिक और जिम्मेदारी से प्राप्त किया जाता है।

प्रश्न और उत्तर
प्रश्न उत्तर (क्यूए) प्राकृतिक भाषा प्रसंस्करण का एक उपक्षेत्र है जो मानव भाषा में प्रश्नों के स्वचालित उत्तर देने पर केंद्रित है। क्यूए सिस्टम को व्यापक पाठ और कोड पर प्रशिक्षित किया जाता है, जो उन्हें तथ्यात्मक, परिभाषात्मक और राय-आधारित सहित विभिन्न प्रकार के प्रश्नों को संभालने में सक्षम बनाता है। ग्राहक सहायता, स्वास्थ्य देखभाल या आपूर्ति श्रृंखला जैसे विशिष्ट क्षेत्रों के अनुरूप क्यूए मॉडल विकसित करने के लिए डोमेन ज्ञान महत्वपूर्ण है। हालाँकि, जेनेरिक क्यूए दृष्टिकोण मॉडल को केवल संदर्भ पर निर्भर करते हुए, डोमेन ज्ञान के बिना पाठ उत्पन्न करने की अनुमति देता है।
विशेषज्ञों की हमारी टीम प्रश्न-उत्तर जोड़े बनाने के लिए व्यापक दस्तावेजों या मैनुअल का सावधानीपूर्वक अध्ययन कर सकती है, जिससे व्यवसायों के लिए जेनरेटिव एआई के निर्माण की सुविधा मिल सके। यह दृष्टिकोण व्यापक कोष से प्रासंगिक जानकारी प्राप्त करके उपयोगकर्ता की पूछताछ से प्रभावी ढंग से निपट सकता है। हमारे प्रमाणित विशेषज्ञ विभिन्न विषयों और डोमेन में फैले उच्च गुणवत्ता वाले प्रश्नोत्तर जोड़े का उत्पादन सुनिश्चित करते हैं।

पाठ का सारांश
हमारे विशेषज्ञ व्यापक पाठ डेटा से संक्षिप्त और व्यावहारिक सारांश प्रदान करते हुए, व्यापक बातचीत या लंबे संवादों को प्रसारित करने में सक्षम हैं।

टेक्स्ट जनरेशन
समाचार लेख, कथा और कविता जैसी विविध शैलियों में पाठ के व्यापक डेटासेट का उपयोग करके मॉडल को प्रशिक्षित करें। ये मॉडल विभिन्न प्रकार की सामग्री उत्पन्न कर सकते हैं, जिसमें समाचार अंश, ब्लॉग प्रविष्टियाँ, या सोशल मीडिया पोस्ट शामिल हैं, जो सामग्री निर्माण के लिए लागत प्रभावी और समय बचाने वाला समाधान पेश करते हैं।
वाक् पहचान
विभिन्न अनुप्रयोगों के लिए बोली जाने वाली भाषा को समझने में सक्षम मॉडल विकसित करें। इसमें ध्वनि-सक्रिय सहायक, श्रुतलेख सॉफ़्टवेयर और वास्तविक समय अनुवाद उपकरण शामिल हैं। इस प्रक्रिया में एक व्यापक डेटासेट का उपयोग शामिल है जिसमें बोली जाने वाली भाषा की ऑडियो रिकॉर्डिंग शामिल होती है, जो उनके संबंधित प्रतिलेखों के साथ जोड़ी जाती है।

उत्पाद की सिफारिशें
ग्राहक खरीद इतिहास के व्यापक डेटासेट का उपयोग करके मॉडल विकसित करें, जिसमें ऐसे लेबल शामिल हों जो उन उत्पादों को इंगित करते हों जिन्हें ग्राहक खरीदना चाहते हैं। लक्ष्य ग्राहकों को सटीक सुझाव प्रदान करना है, जिससे बिक्री बढ़े और ग्राहक संतुष्टि बढ़े।
छवि कैप्शनिंग
हमारी अत्याधुनिक, एआई-संचालित इमेज कैप्शनिंग सेवा के साथ अपनी छवि व्याख्या प्रक्रिया में क्रांति लाएं। हम सटीक और प्रासंगिक रूप से सार्थक विवरण प्रस्तुत करके चित्रों में जीवन शक्ति का संचार करते हैं। यह आपके दर्शकों के लिए आपकी दृश्य सामग्री के साथ नवीन जुड़ाव और बातचीत की संभावनाओं का मार्ग प्रशस्त करता है।

पाठ से वाक् सेवाओं का प्रशिक्षण
हम मानव भाषण ऑडियो रिकॉर्डिंग से युक्त एक व्यापक डेटासेट प्रदान करते हैं, जो एआई मॉडल के प्रशिक्षण के लिए आदर्श है। ये मॉडल आपके एप्लिकेशन के लिए प्राकृतिक और आकर्षक आवाजें उत्पन्न करने में सक्षम हैं, इस प्रकार आपके उपयोगकर्ताओं के लिए एक विशिष्ट और गहन ध्वनि अनुभव प्रदान करते हैं।



