

व्यक्तिगत पहचान योग्य जानकारी (पीआईआई)
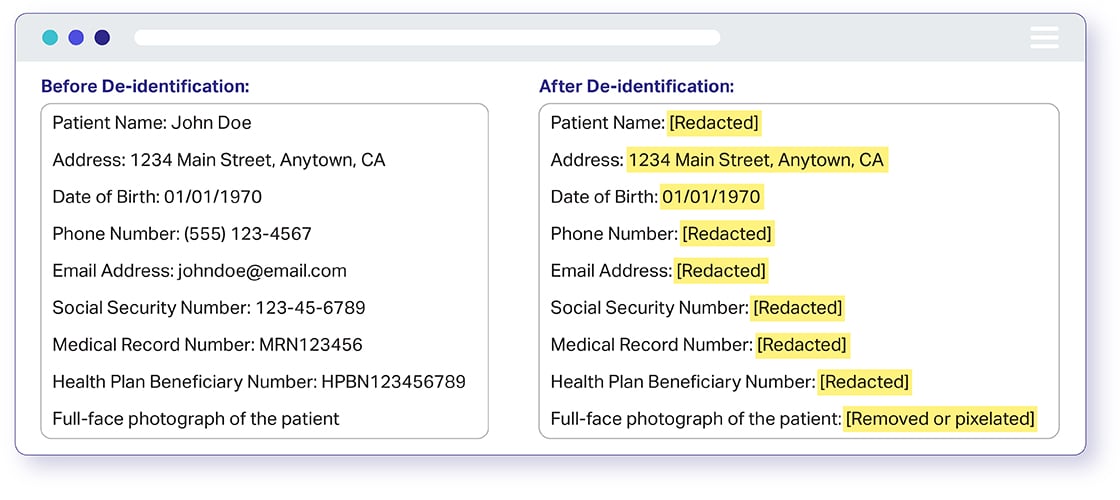
पीआईआई डेटा डी-आइडेंटिफिकेशन या पीआईआई डेटा एनोनिमाइजेशन किसी भी जानकारी को डी-आइडेंटिफाई करने की प्रक्रिया है जो किसी व्यक्ति की पहचान की अनुमति देती है जिस पर पहचानी गई जानकारी लागू होती है या प्रत्यक्ष या अप्रत्यक्ष माध्यमों से उचित अनुमान लगाया जा सकता है। संक्षेप में, व्यक्तिगत रूप से पहचान योग्य जानकारी (पीआईआई) कोई भी डेटा है जो किसी विशिष्ट व्यक्ति से संपर्क कर सकती है, उसका पता लगा सकती है या उसकी पहचान कर सकती है।
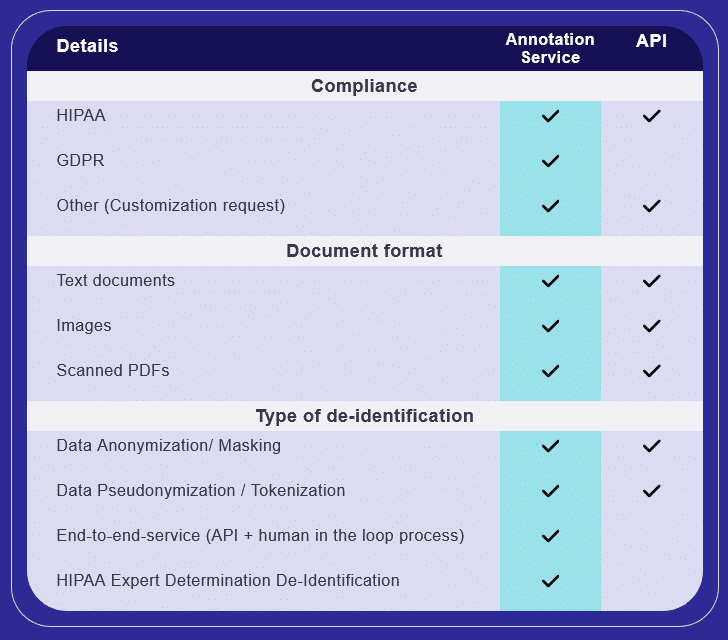
HIPAA डी-आइडेंटिफिकेशन मानक पहचानकर्ताओं या डेटा तत्वों में से कुछ जिनका उपयोग किसी व्यक्ति की पहचान के लिए किया जा सकता है, उनमें शामिल हैं:
| PII में शामिल हैं: नाम, ईमेल, घर का पता, फ़ोन # | |
|---|---|
| यदि स्टैंडअलोन | यदि किसी अन्य पहचानकर्ता के साथ जोड़ा गया है |
| सामाजिक सुरक्षा संख्या | नागरिकता या आप्रवासन स्थिति |
| ड्राइवर का लाइसेंस या राज्य आईडी | मां का विवाह - पूर्व नाम |
| पासपोर्ट संख्या | जातीय या धार्मिक संबद्धता |
| विदेशी पंजीकरण संख्या | धूम्रपान की ओर रुख |
| वित्तीय खाता संख्या | खाता पासवर्ड |
| बायोमेट्रिक पहचानकर्ता | एसएसएन के अंतिम 4 अंक |
| टेलीफ़ोन नंबर | जन्म तिथि |
| ईमेल पता | आपराधिक इतिहास |
| पूरे चेहरे की तस्वीरें | |

संरक्षित स्वास्थ्य सूचना (PHI)
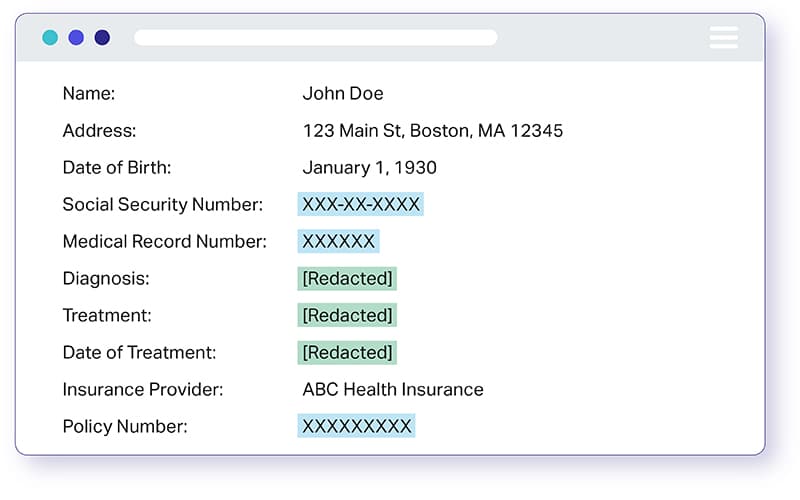
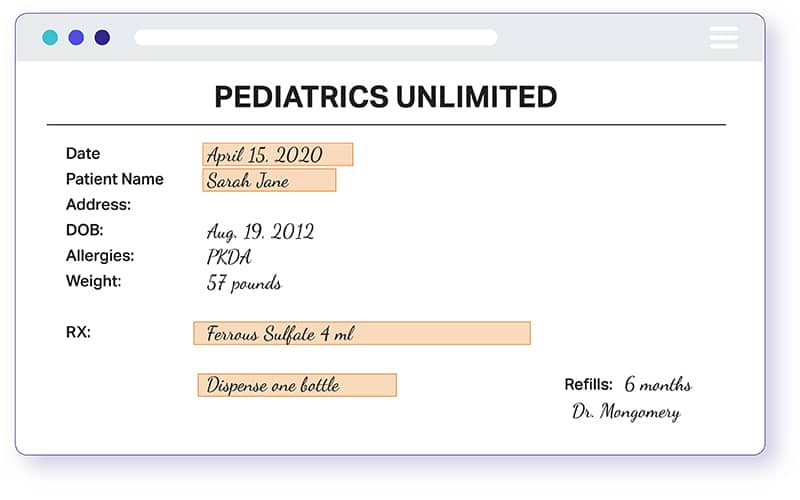
PHI डेटा डी-आइडेंटिफिकेशन या PHI डेटा एनोनिमाइजेशन एक मेडिकल रिकॉर्ड में किसी भी जानकारी को डी-आइडेंटिफाई करने की प्रक्रिया है जिसका उपयोग किसी व्यक्ति की पहचान करने के लिए किया जा सकता है; जो निदान या उपचार जैसी चिकित्सा सेवा प्रदान करने के दौरान बनाई, उपयोग की गई या प्रकट की गई थी। संक्षेप में संरक्षित स्वास्थ्य सूचना (PHI) कोई भी डेटा है जो किसी विशिष्ट व्यक्ति से संपर्क कर सकता है, उसका पता लगा सकता है या उसकी पहचान कर सकता है।
HIPAA पहचानकर्ताओं या डेटा तत्वों में से कुछ जिनका उपयोग किसी व्यक्ति की पहचान करने के लिए किया जा सकता है:
- चिकित्सा छवियां, रिकॉर्ड, स्वास्थ्य योजना लाभार्थी, प्रमाणपत्र, सामाजिक सुरक्षा और खाता संख्या
- किसी व्यक्ति का अतीत, वर्तमान या भविष्य का स्वास्थ्य या स्थिति
- किसी व्यक्ति को स्वास्थ्य देखभाल के प्रावधान के लिए अतीत, वर्तमान या भविष्य का भुगतान
- प्रत्येक तिथि सीधे किसी व्यक्ति से जुड़ी होती है, जैसे जन्म तिथि, डिस्चार्ज तिथि, मृत्यु की तिथि और प्रशासन



स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा निर्माण, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम

प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप

मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण
स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा निर्माण, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम
प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप
मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण


