



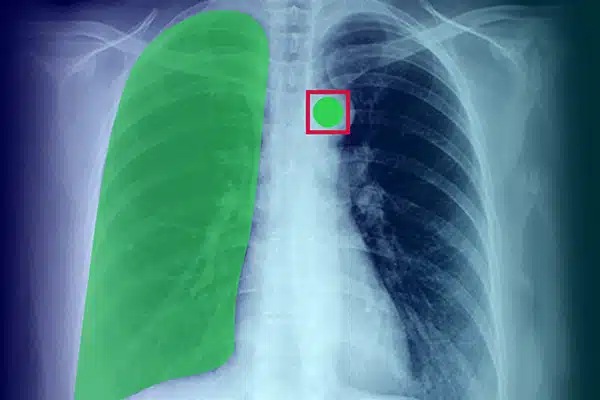
छवि एनोटेशन
एक्स-रे, सीटी स्कैन और एमआरआई से दृश्य डेटा को एनोटेट करके मेडिकल एआई को बढ़ाएं। सुनिश्चित करें कि विशेषज्ञ डेटा लेबलिंग द्वारा निर्देशित एआई मॉडल निदान और उपचार में उत्कृष्ट प्रदर्शन करें। बेहतर इमेजिंग अंतर्दृष्टि के साथ बेहतर रोगी परिणाम प्राप्त करें।
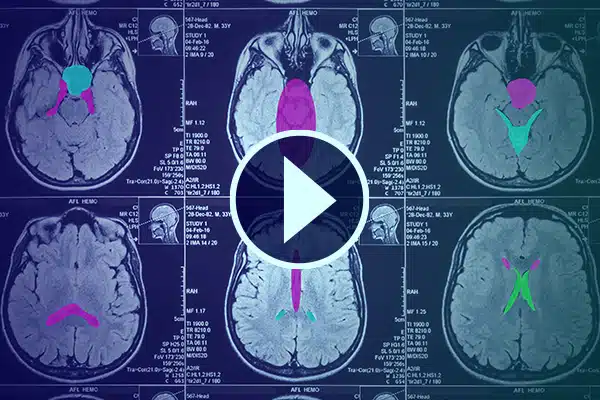
वीडियो एनोटेशन
विस्तृत वीडियो एनोटेशन के साथ स्वास्थ्य सेवा में उन्नत एआई। मेडिकल फ़ुटेज में वर्गीकरण और विभाजन के साथ एआई सीखने को तेज़ करें। बेहतर स्वास्थ्य सेवा वितरण और निदान के लिए अपने सर्जिकल एआई और रोगी की निगरानी में सुधार करें।
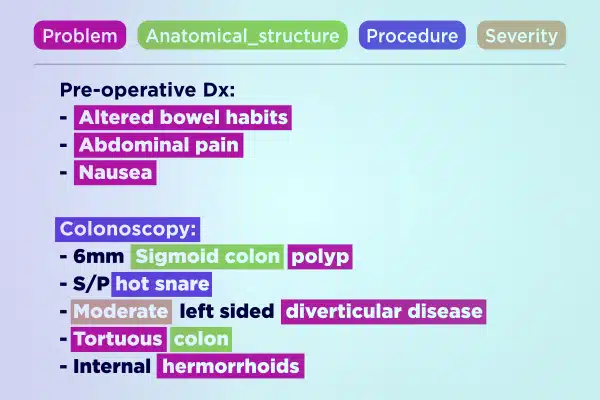
पाठ एनोटेशन
विशेषज्ञ रूप से एनोटेट किए गए टेक्स्ट डेटा के साथ मेडिकल एआई विकास को सुव्यवस्थित करें। हाथ से लिखे नोट्स से लेकर बीमा रिपोर्ट तक, विशाल पाठ्य खंडों को त्वरित रूप से पार्स और समृद्ध करें। स्वास्थ्य देखभाल की प्रगति के लिए सटीक और कार्रवाई योग्य अंतर्दृष्टि सुनिश्चित करें।

ऑडियो एनोटेशन
मेडिकल ऑडियो डेटा को सटीक रूप से एनोटेट और लेबल करने के लिए एनएलपी विशेषज्ञता का लाभ उठाएं। निर्बाध क्लिनिकल संचालन के लिए वॉयस-असिस्टेड सिस्टम तैयार करें और विभिन्न वॉयस-सक्रिय स्वास्थ्य देखभाल उत्पादों में एआई को एकीकृत करें। विशेषज्ञ ऑडियो डेटा क्यूरेशन के साथ नैदानिक परिशुद्धता बढ़ाएँ।

मेडिकल कोडिंग
एआई मेडिकल कोडिंग के साथ इसे सार्वभौमिक कोड में परिवर्तित करके मेडिकल दस्तावेज़ीकरण को सुव्यवस्थित करें। सटीकता सुनिश्चित करें, बिलिंग दक्षता बढ़ाएं और मेडिकल रिकॉर्ड कोडिंग में अत्याधुनिक एआई सहायता के साथ निर्बाध स्वास्थ्य सेवा वितरण का समर्थन करें।

चरण 1: तकनीकी डोमेन विशेषज्ञता (क्षेत्र और एनोटेशन दिशानिर्देशों को समझें)

चरण 2: परियोजना के लिए उपयुक्त संसाधनों का प्रशिक्षण

चरण 3: एनोटेट दस्तावेजों का फीडबैक चक्र और क्यूए
रेडियोलोजी
हमारी रेडियोलॉजी छवि एनोटेशन सेवा एआई डायग्नोस्टिक्स को तेज करती है और इसमें विशेषज्ञता की एक अतिरिक्त परत शामिल है। प्रत्येक एक्स-रे, एमआरआई और सीटी स्कैन को विषय वस्तु विशेषज्ञ द्वारा सावधानीपूर्वक लेबल किया जाता है और समीक्षा की जाती है। प्रशिक्षण और समीक्षा में यह अतिरिक्त कदम एआई की असामान्यताओं और बीमारियों का पता लगाने की क्षमता को बढ़ाता है। यह हमारे ग्राहकों को डिलीवरी से पहले सटीकता बढ़ाता है।

हृदयरोगविज्ञान
हमारा कार्डियोलॉजी-केंद्रित छवि एनोटेशन एआई डायग्नोस्टिक्स को तेज करता है। हम कार्डियोलॉजी विशेषज्ञों को लाते हैं जो जटिल हृदय-संबंधी छवियों को लेबल करते हैं और हमारे एआई मॉडल को प्रशिक्षित करते हैं। इससे पहले कि हम ग्राहकों को डेटा भेजें, ये विशेषज्ञ उच्चतम सटीकता सुनिश्चित करने के लिए प्रत्येक छवि की समीक्षा करते हैं। यह प्रक्रिया एआई को हृदय संबंधी स्थितियों का अधिक सटीकता से पता लगाने में सक्षम बनाती है।
दन्त चिकित्सा
दंत चिकित्सा में हमारी छवि एनोटेशन सेवा एआई डायग्नोस्टिक टूल को बढ़ाने के लिए दंत इमेजरी लेबल करती है। दांतों की सड़न, संरेखण समस्याओं और अन्य दंत स्थितियों की सटीक पहचान करके, हमारे एसएमई रोगी के परिणामों में सुधार करने और सटीक उपचार योजना और शीघ्र पता लगाने में दंत चिकित्सकों का समर्थन करने के लिए एआई को सशक्त बनाते हैं।


















स्टाफ़
समर्पित एवं प्रशिक्षित टीमें:
- डेटा निर्माण, लेबलिंग और क्यूए के लिए 30,000+ सहयोगी
- प्रमाणित परियोजना प्रबंधन टीम
- अनुभवी उत्पाद विकास टीम
- टैलेंट पूल सोर्सिंग एवं ऑनबोर्डिंग टीम

प्रक्रिया
उच्चतम प्रक्रिया दक्षता का आश्वासन दिया जाता है:
- मजबूत 6 सिग्मा स्टेज-गेट प्रक्रिया
- 6 सिग्मा ब्लैक बेल्ट की एक समर्पित टीम - मुख्य प्रक्रिया मालिक और गुणवत्ता अनुपालन
- सतत सुधार एवं फीडबैक लूप

मंच
पेटेंट किया गया प्लेटफ़ॉर्म लाभ प्रदान करता है:
- वेब-आधारित एंड-टू-एंड प्लेटफ़ॉर्म
- त्रुटिहीन गुणवत्ता
- तेज़ TAT
- निर्बाध वितरण



