
यह विधि एआई को यह जानने में मदद करती है कि कब कुछ प्रश्नों से बचना है। यह उन अनुरोधों को अस्वीकार करना सीखता है जिनमें हिंसा या भेदभाव जैसी हानिकारक सामग्री शामिल होती है।
आरएलएचएफ का उपयोग करने वाले मॉडल का एक प्रसिद्ध उदाहरण है ओपनएआई की चैटजीपीटी. यह मॉडल प्रतिक्रियाओं को बेहतर बनाने और उन्हें अधिक प्रासंगिक और जिम्मेदार बनाने के लिए मानवीय प्रतिक्रिया का उपयोग करता है।
मानव प्रतिक्रिया के साथ सुदृढीकरण सीखने के चरण
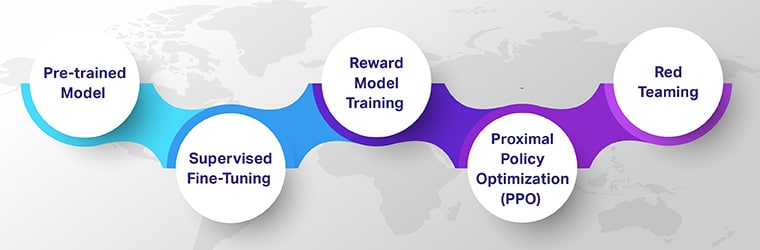
ह्यूमन फीडबैक के साथ सुदृढीकरण सीखना (आरएलएचएफ) यह सुनिश्चित करता है कि एआई मॉडल तकनीकी रूप से कुशल, नैतिक रूप से मजबूत और प्रासंगिक रूप से प्रासंगिक हैं। आरएलएचएफ के पांच प्रमुख चरणों पर गौर करें जो पता लगाते हैं कि वे परिष्कृत, मानव-निर्देशित एआई सिस्टम बनाने में कैसे योगदान करते हैं।
पूर्व-प्रशिक्षित मॉडल से शुरुआत
आरएलएचएफ यात्रा एक पूर्व-प्रशिक्षित मॉडल के साथ शुरू होती है, जो ह्यूमन-इन-द-लूप मशीन लर्निंग में एक मूलभूत कदम है। प्रारंभ में व्यापक डेटासेट पर प्रशिक्षित, इन मॉडलों में भाषा या अन्य बुनियादी कार्यों की व्यापक समझ होती है लेकिन विशेषज्ञता की कमी होती है।
डेवलपर्स पूर्व-प्रशिक्षित मॉडल से शुरुआत करते हैं और एक महत्वपूर्ण लाभ प्राप्त करते हैं। ये मॉडल पहले ही विशाल मात्रा में डेटा से सीखे जा चुके हैं। इससे उन्हें प्रारंभिक प्रशिक्षण चरण में समय और संसाधन बचाने में मदद मिलती है। यह कदम आगे आने वाले अधिक केंद्रित और विशिष्ट प्रशिक्षण के लिए मंच तैयार करता है।
सुपरवाइज्ड फाइन-ट्यूनिंग
दूसरे चरण में पर्यवेक्षित फाइन-ट्यूनिंग शामिल है, जहां पूर्व-प्रशिक्षित मॉडल किसी विशिष्ट कार्य या डोमेन पर अतिरिक्त प्रशिक्षण से गुजरता है। इस चरण की विशेषता लेबल किए गए डेटा का उपयोग करना है, जो मॉडल को अधिक सटीक और प्रासंगिक रूप से प्रासंगिक आउटपुट उत्पन्न करने में मदद करता है।
यह फाइन-ट्यूनिंग प्रक्रिया मानव-निर्देशित एआई प्रशिक्षण का एक प्रमुख उदाहरण है, जहां मानव निर्णय एआई को वांछित व्यवहार और प्रतिक्रियाओं की ओर ले जाने में महत्वपूर्ण भूमिका निभाता है। प्रशिक्षकों को डोमेन-विशिष्ट डेटा का सावधानीपूर्वक चयन और प्रस्तुत करना चाहिए ताकि यह सुनिश्चित हो सके कि एआई कार्य की बारीकियों और विशिष्ट आवश्यकताओं के अनुकूल है।
पुरस्कार मॉडल प्रशिक्षण
तीसरे चरण में, आप एआई द्वारा उत्पन्न वांछनीय आउटपुट को पहचानने और पुरस्कृत करने के लिए एक अलग मॉडल को प्रशिक्षित करते हैं। यह कदम फीडबैक-आधारित एआई लर्निंग का केंद्र है।
इनाम मॉडल एआई के आउटपुट का मूल्यांकन करता है। यह प्रासंगिकता, सटीकता और वांछित परिणामों के साथ संरेखण जैसे मानदंडों के आधार पर स्कोर प्रदान करता है। ये स्कोर फीडबैक के रूप में कार्य करते हैं और एआई को उच्च-गुणवत्ता वाली प्रतिक्रियाएं उत्पन्न करने के लिए मार्गदर्शन करते हैं। यह प्रक्रिया जटिल या व्यक्तिपरक कार्यों की अधिक सूक्ष्म समझ को सक्षम बनाती है जहां प्रभावी प्रशिक्षण के लिए स्पष्ट निर्देश अपर्याप्त हो सकते हैं।
समीपस्थ नीति अनुकूलन (पीपीओ) के माध्यम से सुदृढीकरण सीखना
इसके बाद, एआई प्रॉक्सिमल पॉलिसी ऑप्टिमाइज़ेशन (पीपीओ) के माध्यम से सुदृढीकरण सीखने से गुजरता है, जो इंटरैक्टिव मशीन लर्निंग में एक परिष्कृत एल्गोरिदमिक दृष्टिकोण है।
पीपीओ एआई को अपने पर्यावरण के साथ सीधे संपर्क से सीखने की अनुमति देता है। यह पुरस्कार और दंड के माध्यम से अपनी निर्णय लेने की प्रक्रिया को परिष्कृत करता है। यह विधि वास्तविक समय सीखने और अनुकूलन में विशेष रूप से प्रभावी है, क्योंकि यह एआई को विभिन्न परिदृश्यों में अपने कार्यों के परिणामों को समझने में मदद करती है।
पीपीओ एआई को जटिल, गतिशील वातावरण में नेविगेट करना सिखाने में सहायक है जहां वांछित परिणाम विकसित हो सकते हैं या परिभाषित करना मुश्किल हो सकता है।
रेड टीमिंग
अंतिम चरण में एआई प्रणाली का कठोर वास्तविक-विश्व परीक्षण शामिल है। यहां, मूल्यांकनकर्ताओं का एक विविध समूह, जिसे 'के नाम से जाना जाता है'लाल समूह,' विभिन्न परिदृश्यों के साथ एआई को चुनौती दें। वे इसकी सटीक और उचित प्रतिक्रिया देने की क्षमता का परीक्षण करते हैं। यह चरण सुनिश्चित करता है कि एआई वास्तविक दुनिया के अनुप्रयोगों और अप्रत्याशित स्थितियों को संभाल सकता है।
रेड टीमिंग एआई की तकनीकी दक्षता और नैतिक और प्रासंगिक सुदृढ़ता का परीक्षण करती है। वे सुनिश्चित करते हैं कि यह स्वीकार्य नैतिक और सांस्कृतिक सीमाओं के भीतर संचालित हो।
इन सभी चरणों में, आरएलएचएफ एआई विकास के हर चरण में मानव भागीदारी के महत्व पर जोर देता है। सावधानीपूर्वक तैयार किए गए डेटा के साथ प्रारंभिक प्रशिक्षण का मार्गदर्शन करने से लेकर सूक्ष्म प्रतिक्रिया और कठोर वास्तविक दुनिया परीक्षण प्रदान करने तक, मानव इनपुट एआई सिस्टम बनाने के लिए अभिन्न अंग है जो बुद्धिमान, जिम्मेदार और मानवीय मूल्यों और नैतिकता के अनुरूप हैं।
निष्कर्ष
ह्यूमन फीडबैक के साथ रीइनफोर्समेंट लर्निंग (आरएलएचएफ) एआई में एक नए युग को दर्शाता है क्योंकि यह अधिक नैतिक, सटीक एआई सिस्टम के लिए मशीन लर्निंग के साथ मानवीय अंतर्दृष्टि को मिश्रित करता है।
आरएलएचएफ एआई को अधिक सशक्त, समावेशी और नवीन बनाने का वादा करता है। यह पूर्वाग्रहों को संबोधित कर सकता है और समस्या-समाधान को बढ़ा सकता है। यह स्वास्थ्य सेवा, शिक्षा और ग्राहक सेवा जैसे क्षेत्रों में बदलाव लाने के लिए तैयार है।
हालाँकि, इस दृष्टिकोण को परिष्कृत करने के लिए प्रभावशीलता, निष्पक्षता और नैतिक संरेखण सुनिश्चित करने के लिए निरंतर प्रयासों की आवश्यकता है।


