
स्वचालित भाषण पहचान प्रणाली और सिरी, एलेक्सा और कोरटाना जैसे आभासी सहायक हमारे जीवन का सामान्य हिस्सा बन गए हैं। जैसे-जैसे वे होशियार होते जाते हैं, उन पर हमारी निर्भरता काफी बढ़ती जाती है। अपनी रोशनी चालू करने से लेकर कॉल करने से लेकर टीवी चैनल बदलने तक, हम सांसारिक कार्यों को पूरा करने के लिए इन स्मार्ट तकनीकों का लाभ उठाते हैं।
हालाँकि, क्या आपने कभी सोचा है कि ये स्पीच रिकग्निशन सिस्टम कैसे काम करते हैं?
खैर, यह ब्लॉग आपको स्वचालित वाक् पहचान के कुछ मूल सिद्धांतों पर शिक्षित करेगा। इसके अलावा, हम इसकी कार्यप्रणाली और सिरी जैसे कार्यात्मक आभासी सहायकों के निर्माण का पता लगाएंगे।
स्वचालित वाक् पहचान क्या है?
स्वचालित भाषण पहचान (एएसआर) सॉफ्टवेयर है जो कंप्यूटर सिस्टम को मानव भाषण को पाठ में परिवर्तित करने में सक्षम बनाता है, कई कृत्रिम बुद्धि और मशीन लर्निंग एल्गोरिदम का लाभ उठाता है।
दिए गए कमांड को बदलने और उसका विश्लेषण करने के बाद, कंप्यूटर उपयोगकर्ता के लिए उपयुक्त आउटपुट के साथ प्रतिक्रिया करता है। ASR को पहली बार 1962 में पेश किया गया था, और तब से, यह लगातार अपने संचालन में सुधार कर रहा है और एलेक्सा और सिरी जैसे लोकप्रिय अनुप्रयोगों के कारण बड़ी लाइमलाइट प्राप्त कर रहा है।
एएसआर मॉडल के प्रशिक्षण के लिए भाषण संग्रह की प्रक्रिया क्या है?
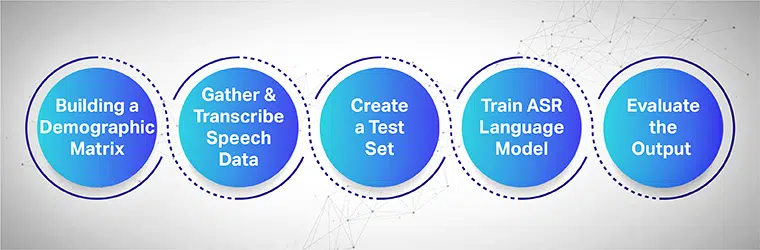
भाषण संग्रह का उद्देश्य एएसआर मॉडल को खिलाने और प्रशिक्षित करने के लिए उपयोग किए जाने वाले कई क्षेत्रों से कई नमूना रिकॉर्डिंग एकत्र करना है। एएसआर सिस्टम उच्चतम दक्षता प्रदान करता है जब भाषण और ऑडियो के बड़े डेटासेट एकत्र किए जाते हैं और इसके सिस्टम को प्रदान किए जाते हैं।
समेकित रूप से काम करने के लिए, एकत्रित भाषण डेटासेट में सभी लक्षित जनसांख्यिकी, भाषाएं, लहजे और बोलियां शामिल होनी चाहिए। निम्नलिखित प्रक्रिया दिखाती है कि मशीन लर्निंग मॉडल को कई चरणों में कैसे प्रशिक्षित किया जाए:
एक जनसांख्यिकीय मैट्रिक्स का निर्माण करके प्रारंभ करें
मुख्य रूप से स्थान, लिंग, भाषा, आयु और उच्चारण जैसे विभिन्न जनसांख्यिकी के लिए डेटा एकत्र करता है। इसके अलावा, सड़क के शोर, प्रतीक्षालय के शोर, सार्वजनिक कार्यालय के शोर आदि जैसे विभिन्न पर्यावरणीय शोरों को पकड़ना सुनिश्चित करें।
स्पीच डेटा को इकट्ठा और ट्रांसक्राइब करें
अगला कदम आपके एएसआर मॉडल को प्रशिक्षित करने के लिए विभिन्न भौगोलिक स्थानों के आधार पर मानव ऑडियो और भाषण के नमूने एकत्र कर रहा है। यह एक महत्वपूर्ण कदम है और वाक्य का वास्तविक अनुभव प्राप्त करने के लिए मानव विशेषज्ञों को शब्दों के लंबे और छोटे उच्चारण करने की आवश्यकता होती है और विभिन्न उच्चारणों और बोलियों में एक ही वाक्य को दोहराते हैं।
एक अलग टेस्ट सेट बनाएँ
एक बार जब आप लिप्यंतरित पाठ एकत्र कर लेते हैं, तो अगला चरण इसे संबंधित ऑडियो डेटा के साथ जोड़ना है। फिर, डेटा को और खंडित करें और उनमें से एक कथन शामिल करें। अब, खंडित डेटा जोड़े से, आप आगे के परीक्षण के लिए एक सेट से यादृच्छिक डेटा खींच सकते हैं।
अपने एएसआर भाषा मॉडल को प्रशिक्षित करें
आपके डेटासेट में जितनी अधिक जानकारी होगी, आपका AI-प्रशिक्षित मॉडल उतना ही बेहतर प्रदर्शन करेगा। इसलिए, आपके द्वारा पहले रिकॉर्ड किए गए पाठ और भाषणों के कई रूप उत्पन्न करें। अलग-अलग स्पीच नोटेशन का उपयोग करते हुए एक ही वाक्य को पैराफ्रेश करें।
आउटपुट का मूल्यांकन करें और अंत में, पुनरावृति करें
अंत में, अपने प्रदर्शन को ठीक करने के लिए अपने ASR मॉडल के आउटपुट को मापें। इसकी दक्षता निर्धारित करने के लिए एक परीक्षण सेट के विरुद्ध मॉडल का परीक्षण करें। उचित रूप से, वांछित आउटपुट उत्पन्न करने और किसी भी अंतराल को ठीक करने के लिए अपने एएसआर मॉडल को फीडबैक लूप में संलग्न करें।
[ये भी पढ़ें: स्वचालित वाक् पहचान का व्यापक अवलोकन]

वाक् पहचान के विभिन्न उपयोग मामले क्या हैं?
भाषण पहचान तकनीक आज कई उद्योगों में अत्यधिक प्रचलित है। इस जबरदस्त तकनीक का उपयोग करने वाले कुछ उद्योग इस प्रकार हैं:
 खाद्य उद्योग: वेंडीज और मैकडॉनल्ड्स जैसे खाद्य दिग्गज एएसआर का उपयोग करके अपने ग्राहकों के अनुभव को बढ़ाने के लिए तैयार हैं। अपने कई आउटलेट्स में, उन्होंने ऑर्डर लेने के लिए पूरी तरह कार्यात्मक एएसआर मॉडल तैनात किए हैं, और ग्राहक ऑर्डर तैयार करने के लिए उन्हें कुकिंग सेक्शन में भेज दिया है।
खाद्य उद्योग: वेंडीज और मैकडॉनल्ड्स जैसे खाद्य दिग्गज एएसआर का उपयोग करके अपने ग्राहकों के अनुभव को बढ़ाने के लिए तैयार हैं। अपने कई आउटलेट्स में, उन्होंने ऑर्डर लेने के लिए पूरी तरह कार्यात्मक एएसआर मॉडल तैनात किए हैं, और ग्राहक ऑर्डर तैयार करने के लिए उन्हें कुकिंग सेक्शन में भेज दिया है।- दूरसंचार: वोडाफोन दुनिया के सबसे बड़े दूरसंचार प्रदाताओं में से एक है। इसने अपनी ग्राहक सेवा और टेलीफोन रिले सेवाओं को एएसआर मॉडल का लाभ उठाने के लिए डिज़ाइन किया है जो आपको विभिन्न प्रश्नों को हल करने और संबंधित विभागों को आपकी कॉल को फिर से रूट करने के लिए मार्गदर्शन करता है।
- यात्रा और परिवहन: Google Android Auto या Apple CarPlay आम हो गए हैं। अधिकांश लोग उनका उपयोग नेविगेशन सिस्टम को सक्रिय करने, संदेश भेजने या संगीत प्लेलिस्ट बदलने के लिए करते हैं। हालाँकि, तकनीकी प्रगति के साथ, ऐसी प्रणालियाँ अधिक परिष्कृत होती जा रही हैं।
BMW 3 सीरीज में लॉन्च किया गया BMW इंटेलिजेंट पर्सनल असिस्टेंट रेगुलर वॉयस असिस्टेंट के मुकाबले ज्यादा स्मार्ट है। यह ड्राइवरों को कार से संबंधित जानकारी खोजने और वॉयस कमांड का उपयोग करके कार चलाने में सक्षम बनाता है। - मीडिया और मनोरंजन: मीडिया उद्योग भी अपनी कई परियोजनाओं में एएसआर का उपयोग करता है। Youtube ने AI-आधारित सहायक लॉन्च किया है जो लाइव ऑटो-कैप्शन उत्पन्न करता है। जैसे ही आप स्क्रीन पर बोलते हैं, सहायक वीडियो को Youtube उपयोगकर्ताओं के एक बड़े समूह के लिए सुलभ बनाने के लिए उपशीर्षक प्रदान करेगा।
 खाद्य उद्योग: वेंडीज और मैकडॉनल्ड्स जैसे खाद्य दिग्गज एएसआर का उपयोग करके अपने ग्राहकों के अनुभव को बढ़ाने के लिए तैयार हैं। अपने कई आउटलेट्स में, उन्होंने ऑर्डर लेने के लिए पूरी तरह कार्यात्मक एएसआर मॉडल तैनात किए हैं, और ग्राहक ऑर्डर तैयार करने के लिए उन्हें कुकिंग सेक्शन में भेज दिया है।
खाद्य उद्योग: वेंडीज और मैकडॉनल्ड्स जैसे खाद्य दिग्गज एएसआर का उपयोग करके अपने ग्राहकों के अनुभव को बढ़ाने के लिए तैयार हैं। अपने कई आउटलेट्स में, उन्होंने ऑर्डर लेने के लिए पूरी तरह कार्यात्मक एएसआर मॉडल तैनात किए हैं, और ग्राहक ऑर्डर तैयार करने के लिए उन्हें कुकिंग सेक्शन में भेज दिया है। दूरसंचार: वोडाफोन दुनिया के सबसे बड़े दूरसंचार प्रदाताओं में से एक है। इसने अपनी ग्राहक सेवा और टेलीफोन रिले सेवाओं को एएसआर मॉडल का लाभ उठाने के लिए डिज़ाइन किया है जो आपको विभिन्न प्रश्नों को हल करने और संबंधित विभागों को आपकी कॉल को फिर से रूट करने के लिए मार्गदर्शन करता है।
दूरसंचार: वोडाफोन दुनिया के सबसे बड़े दूरसंचार प्रदाताओं में से एक है। इसने अपनी ग्राहक सेवा और टेलीफोन रिले सेवाओं को एएसआर मॉडल का लाभ उठाने के लिए डिज़ाइन किया है जो आपको विभिन्न प्रश्नों को हल करने और संबंधित विभागों को आपकी कॉल को फिर से रूट करने के लिए मार्गदर्शन करता है। यात्रा और परिवहन: Google Android Auto या Apple CarPlay आम हो गए हैं। अधिकांश लोग उनका उपयोग नेविगेशन सिस्टम को सक्रिय करने, संदेश भेजने या संगीत प्लेलिस्ट बदलने के लिए करते हैं। हालाँकि, तकनीकी प्रगति के साथ, ऐसी प्रणालियाँ अधिक परिष्कृत होती जा रही हैं।
यात्रा और परिवहन: Google Android Auto या Apple CarPlay आम हो गए हैं। अधिकांश लोग उनका उपयोग नेविगेशन सिस्टम को सक्रिय करने, संदेश भेजने या संगीत प्लेलिस्ट बदलने के लिए करते हैं। हालाँकि, तकनीकी प्रगति के साथ, ऐसी प्रणालियाँ अधिक परिष्कृत होती जा रही हैं। मीडिया और मनोरंजन: मीडिया उद्योग भी अपनी कई परियोजनाओं में एएसआर का उपयोग करता है। Youtube ने AI-आधारित सहायक लॉन्च किया है जो लाइव ऑटो-कैप्शन उत्पन्न करता है। जैसे ही आप स्क्रीन पर बोलते हैं, सहायक वीडियो को Youtube उपयोगकर्ताओं के एक बड़े समूह के लिए सुलभ बनाने के लिए उपशीर्षक प्रदान करेगा।
मीडिया और मनोरंजन: मीडिया उद्योग भी अपनी कई परियोजनाओं में एएसआर का उपयोग करता है। Youtube ने AI-आधारित सहायक लॉन्च किया है जो लाइव ऑटो-कैप्शन उत्पन्न करता है। जैसे ही आप स्क्रीन पर बोलते हैं, सहायक वीडियो को Youtube उपयोगकर्ताओं के एक बड़े समूह के लिए सुलभ बनाने के लिए उपशीर्षक प्रदान करेगा।
[ये भी पढ़ें: स्पीच-टू-टेक्स्ट टेक्नोलॉजी क्या है और यह कैसे काम करती है]
शिप कैसे मदद कर सकता है?
Shaip अग्रणी AI प्रशिक्षण सेवाओं में से एक है जो AI और ML के कई क्षेत्रों में विशेषज्ञता रखती है। वे आपका अपना डेटा सेट बनाने में आपकी मदद कर सकते हैं जिसका उपयोग विभिन्न अनुप्रयोगों और परियोजनाओं के लिए किया जा सकता है।
शिप द्वारा प्रदान की जाने वाली कुछ सेवाएं हैं:
- स्वचालित वाक् पहचान (एएसआर)
- लिखित भाषण संग्रह
- ट्रांसक्रिएशन
- सहज भाषण संग्रह
- उच्चारण संग्रह / जागो-अप शब्द,
- टेक्स्ट-टू-स्पीच (टीटीएस)
आप अपनी एआई-आधारित परियोजनाओं के लिए सर्वोत्तम परिणाम प्राप्त करने के लिए इन सेवाओं का लाभ उठा सकते हैं। आज ही हमारी विशेषज्ञ टीम से संपर्क करके इन सेवाओं के बारे में और जानें!


