
आर्टिफिशियल इंटेलिजेंस और बिग डेटा में स्थानीय मुद्दों को प्राथमिकता देते हुए और दुनिया को कई गहन तरीकों से बदलने के दौरान वैश्विक समस्याओं का समाधान खोजने की क्षमता है। एआई सभी के लिए - और सभी सेटिंग्स में, घरों से कार्यस्थलों तक समाधान लाता है। एआई कंप्यूटर, के साथ मशीन लर्निंग प्रशिक्षण, एक स्वचालित अभी तक वैयक्तिकृत तरीके से बुद्धिमान व्यवहार और वार्तालापों का अनुकरण कर सकता है।
फिर भी, एआई एक समावेशन समस्या का सामना करता है और अक्सर पक्षपाती होता है। सौभाग्य से ध्यान केंद्रित कर रहा है कृत्रिम बुद्धि नैतिकता विविध प्रशिक्षण डेटा के माध्यम से अचेतन पूर्वाग्रह को समाप्त करके विविधीकरण और समावेशन के संदर्भ में नई संभावनाओं की शुरूआत कर सकते हैं।
एआई प्रशिक्षण डेटा में विविधता का महत्व
 प्रशिक्षण डेटा की विविधता और गुणवत्ता संबंधित हैं क्योंकि एक दूसरे को प्रभावित करता है और एआई समाधान के परिणाम को प्रभावित करता है। एआई समाधान की सफलता इस पर निर्भर करती है विविध डेटा इसे प्रशिक्षित किया जाता है। डेटा विविधता एआई को ओवरफिटिंग से रोकती है - जिसका अर्थ है कि मॉडल केवल प्रशिक्षण के लिए उपयोग किए गए डेटा से प्रदर्शन या सीखता है। ओवरफिटिंग के साथ, एआई मॉडल प्रशिक्षण में उपयोग नहीं किए गए डेटा पर परीक्षण किए जाने पर परिणाम प्रदान नहीं कर सकता है।
प्रशिक्षण डेटा की विविधता और गुणवत्ता संबंधित हैं क्योंकि एक दूसरे को प्रभावित करता है और एआई समाधान के परिणाम को प्रभावित करता है। एआई समाधान की सफलता इस पर निर्भर करती है विविध डेटा इसे प्रशिक्षित किया जाता है। डेटा विविधता एआई को ओवरफिटिंग से रोकती है - जिसका अर्थ है कि मॉडल केवल प्रशिक्षण के लिए उपयोग किए गए डेटा से प्रदर्शन या सीखता है। ओवरफिटिंग के साथ, एआई मॉडल प्रशिक्षण में उपयोग नहीं किए गए डेटा पर परीक्षण किए जाने पर परिणाम प्रदान नहीं कर सकता है।
एआई प्रशिक्षण की वर्तमान स्थिति तिथि
डेटा में असमानता या विविधता की कमी से अनुचित, अनैतिक और गैर-समावेशी एआई समाधान होंगे जो भेदभाव को गहरा कर सकते हैं। लेकिन एआई समाधान से संबंधित डेटा में विविधता कैसे और क्यों है?
सभी वर्गों के असमान प्रतिनिधित्व से चेहरों की गलत पहचान होती है - एक महत्वपूर्ण मामला Google फ़ोटो है जिसने एक काले जोड़े को 'गोरिल्ला' के रूप में वर्गीकृत किया है। और मेटा एक उपयोगकर्ता को काले पुरुषों का वीडियो देखने का संकेत देता है कि क्या उपयोगकर्ता 'प्राइमेट्स के वीडियो देखना जारी रखना' चाहेगा।
उदाहरण के लिए, जातीय या नस्लीय अल्पसंख्यकों का गलत या अनुचित वर्गीकरण, विशेष रूप से चैटबॉट्स में, एआई प्रशिक्षण प्रणालियों में पूर्वाग्रह का परिणाम हो सकता है। 2019 की रिपोर्ट के अनुसार भेदभावपूर्ण प्रणालियाँ - AI में लिंग, जाति, शक्तिएआई के 80% से अधिक शिक्षक पुरुष हैं; FB पर महिला AI शोधकर्ता Google पर केवल 15% और 10% हैं।
एआई प्रदर्शन पर विविध प्रशिक्षण डेटा का प्रभाव
 डेटा प्रतिनिधित्व से विशिष्ट समूहों और समुदायों को छोड़ने से तिरछे एल्गोरिदम हो सकते हैं।
डेटा प्रतिनिधित्व से विशिष्ट समूहों और समुदायों को छोड़ने से तिरछे एल्गोरिदम हो सकते हैं।
डेटा पूर्वाग्रह को अक्सर गलती से डेटा सिस्टम में पेश किया जाता है - कुछ नस्लों या समूहों को अंडर-सैंपलिंग करके। जब चेहरे की पहचान प्रणाली को विविध चेहरों पर प्रशिक्षित किया जाता है, तो यह मॉडल को विशिष्ट विशेषताओं की पहचान करने में मदद करता है, जैसे कि चेहरे के अंगों की स्थिति और रंग विविधताएं।
लेबलों की असंतुलित आवृत्ति होने का एक अन्य परिणाम यह है कि जब थोड़े समय के भीतर उत्पादन का उत्पादन करने के लिए दबाव डाला जाता है तो सिस्टम अल्पसंख्यक को एक विसंगति के रूप में मान सकता है।
एआई प्रशिक्षण डेटा में विविधता हासिल करना
दूसरी तरफ, विविध डेटासेट तैयार करना भी एक चुनौती है। कुछ वर्गों पर डेटा की कमी के कारण कम प्रतिनिधित्व हो सकता है। एआई डेवलपर टीमों को कौशल, जातीयता, नस्ल, लिंग, अनुशासन, और बहुत कुछ के संबंध में अधिक विविध बनाकर इसे कम किया जा सकता है। इसके अलावा, एआई में डेटा विविधता की समस्याओं को दूर करने का आदर्श तरीका यह है कि जो किया गया है उसे ठीक करने की कोशिश करने के बजाय शब्द से इसका सामना करना है - डेटा संग्रह और क्यूरेशन चरण में विविधता को प्रभावित करना।
एआई के आसपास प्रचार के बावजूद, यह अभी भी मनुष्यों द्वारा एकत्रित, चयनित और प्रशिक्षित डेटा पर निर्भर करता है। मनुष्यों में जन्मजात पूर्वाग्रह उनके द्वारा एकत्र किए गए डेटा में परिलक्षित होगा, और यह अचेतन पूर्वाग्रह एमएल मॉडल में भी रेंगता है।
विविध प्रशिक्षण डेटा एकत्र करने और क्यूरेट करने के लिए कदम
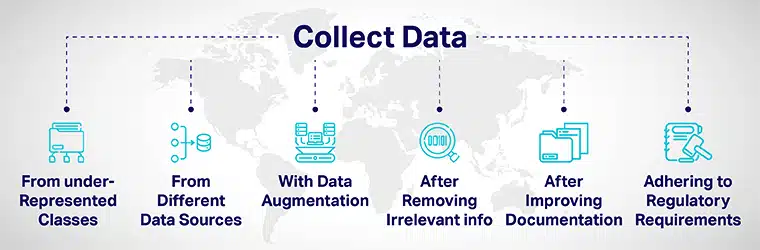
डेटा विविधता द्वारा प्राप्त किया जा सकता है:
- सोच-समझकर कम प्रतिनिधित्व वाली कक्षाओं से अधिक डेटा जोड़ें और अपने मॉडलों को विभिन्न डेटा बिंदुओं पर प्रदर्शित करें।
- विभिन्न डेटा स्रोतों से डेटा एकत्र करके।
- मूल डेटा बिंदुओं से स्पष्ट रूप से अलग नए डेटा बिंदुओं को बढ़ाने / शामिल करने के लिए डेटा वृद्धि या कृत्रिम रूप से डेटासेट में हेरफेर करके।
- एआई विकास प्रक्रिया के लिए आवेदकों को भर्ती करते समय, आवेदन से सभी नौकरी-अप्रासंगिक जानकारी हटा दें।
- मॉडलों के विकास और मूल्यांकन के प्रलेखन में सुधार करके पारदर्शिता और जवाबदेही में सुधार करना।
- विविधता का निर्माण करने के लिए नियमों का परिचय और एआई में समावेशिता जमीनी स्तर से सिस्टम। विभिन्न सरकारों ने विविधता सुनिश्चित करने और एआई पूर्वाग्रह को कम करने के लिए दिशा-निर्देश विकसित किए हैं जो अनुचित परिणाम दे सकते हैं।
[ये भी पढ़ें: एआई प्रशिक्षण डेटा संग्रह प्रक्रिया के बारे में अधिक जानें ]
निष्कर्ष
वर्तमान में, केवल कुछ बड़ी टेक कंपनियां और शिक्षण केंद्र विशेष रूप से एआई समाधान विकसित करने में शामिल हैं। ये संभ्रांत स्थान बहिष्करण, भेदभाव और पूर्वाग्रह में डूबे हुए हैं। हालाँकि, ये ऐसे स्थान हैं जहाँ AI विकसित किया जा रहा है, और इन उन्नत AI सिस्टम के पीछे का तर्क समान पूर्वाग्रह, भेदभाव और बहिष्करण से भरा हुआ है, जो कम प्रतिनिधित्व वाले समूहों द्वारा वहन किया जाता है।
विविधता और गैर-भेदभाव पर चर्चा करते समय, यह सवाल करना महत्वपूर्ण है कि इससे किन लोगों को लाभ होता है और किसे नुकसान होता है। हमें यह भी देखना चाहिए कि यह किसे नुकसान पहुंचाता है - एक 'सामान्य' व्यक्ति के विचार को मजबूर करके, एआई संभावित रूप से 'दूसरों' को जोखिम में डाल सकता है।
शक्ति संबंधों, इक्विटी और न्याय को स्वीकार किए बिना एआई डेटा में विविधता पर चर्चा करने से बड़ी तस्वीर नहीं दिखेगी। एआई प्रशिक्षण डेटा में विविधता के दायरे को पूरी तरह से समझने के लिए और कैसे मनुष्य और एआई मिलकर इस संकट को कम कर सकते हैं, Shaip के इंजीनियरों से संपर्क करें. हमारे पास विविध एआई इंजीनियर हैं जो आपके एआई समाधानों के लिए गतिशील और विविध डेटा प्रदान कर सकते हैं।


