
एआई, बिग डेटा और मशीन लर्निंग दुनिया भर में नीति निर्माताओं, व्यवसायों, विज्ञान, मीडिया घरानों और विभिन्न प्रकार के उद्योगों को प्रभावित करना जारी रखते हैं। रिपोर्टों से पता चलता है कि एआई की वैश्विक गोद लेने की दर वर्तमान में है 35 में 2022% – 4 से 2021% की भारी वृद्धि। अतिरिक्त 42% कंपनियां कथित तौर पर अपने व्यवसाय के लिए एआई के कई लाभों की खोज कर रही हैं।
कई एआई पहलों को शक्ति प्रदान करना और मशीन लर्निंग समाधान डेटा है। एआई केवल एल्गोरिथम को फीड करने वाले डेटा जितना ही अच्छा हो सकता है। निम्न-गुणवत्ता वाले डेटा के परिणामस्वरूप निम्न-गुणवत्ता वाले परिणाम और गलत पूर्वानुमान हो सकते हैं।
जबकि एमएल और एआई समाधान के विकास पर बहुत अधिक ध्यान दिया गया है, गुणवत्ता डेटासेट के रूप में योग्यता के बारे में जागरूकता गायब है। इस लेख में, हम की समयरेखा नेविगेट करते हैं गुणवत्ता एआई प्रशिक्षण डेटा और डेटा संग्रह और प्रशिक्षण की समझ के माध्यम से एआई के भविष्य की पहचान करना।
एआई प्रशिक्षण डेटा की परिभाषा
एमएल समाधान का निर्माण करते समय, प्रशिक्षण डेटासेट की मात्रा और गुणवत्ता मायने रखती है। एमएल प्रणाली को न केवल बड़ी मात्रा में गतिशील, निष्पक्ष और मूल्यवान प्रशिक्षण डेटा की आवश्यकता होती है, बल्कि इसकी बहुत आवश्यकता भी होती है।
लेकिन एआई प्रशिक्षण डेटा क्या है?
एआई प्रशिक्षण डेटा सटीक भविष्यवाणी करने के लिए एमएल एल्गोरिदम को प्रशिक्षित करने के लिए उपयोग किए जाने वाले लेबल किए गए डेटा का एक संग्रह है। एमएल प्रणाली प्रशिक्षण डेटा के आधार पर पैटर्न को पहचानने और पहचानने, मापदंडों के बीच संबंधों को समझने, आवश्यक निर्णय लेने और मूल्यांकन करने की कोशिश करती है।
उदाहरण के लिए सेल्फ ड्राइविंग कारों का उदाहरण लें। स्व-ड्राइविंग एमएल मॉडल के लिए प्रशिक्षण डेटासेट में कारों, पैदल चलने वालों, सड़क के संकेतों और अन्य वाहनों के लेबल वाले चित्र और वीडियो शामिल होने चाहिए।
संक्षेप में, एमएल एल्गोरिथ्म की गुणवत्ता बढ़ाने के लिए, आपको बड़ी मात्रा में अच्छी तरह से संरचित, एनोटेट और लेबल किए गए प्रशिक्षण डेटा की आवश्यकता होती है।
गुणवत्ता प्रशिक्षण डेटा और उसके विकास का महत्व
एआई और एमएल ऐप विकास में उच्च गुणवत्ता वाला प्रशिक्षण डेटा प्रमुख इनपुट है। डेटा विभिन्न स्रोतों से एकत्र किया जाता है और असंगठित रूप में प्रस्तुत किया जाता है जो मशीन सीखने के उद्देश्यों के लिए अनुपयुक्त होता है। गुणवत्ता प्रशिक्षण डेटा - लेबल, एनोटेट और टैग किया गया - हमेशा एक संगठित प्रारूप में होता है - एमएल प्रशिक्षण के लिए आदर्श।
गुणवत्ता प्रशिक्षण डेटा एमएल प्रणाली के लिए वस्तुओं को पहचानना और उन्हें पूर्व निर्धारित सुविधाओं के अनुसार वर्गीकृत करना आसान बनाता है। यदि वर्गीकरण सटीक नहीं है तो डेटासेट खराब मॉडल परिणाम दे सकता है।
एआई प्रशिक्षण डेटा के शुरुआती दिन
एआई वर्तमान व्यवसाय और अनुसंधान की दुनिया पर हावी होने के बावजूद, एमएल के शुरुआती दिनों में हावी था Artificial Intelligence काफी अलग था।
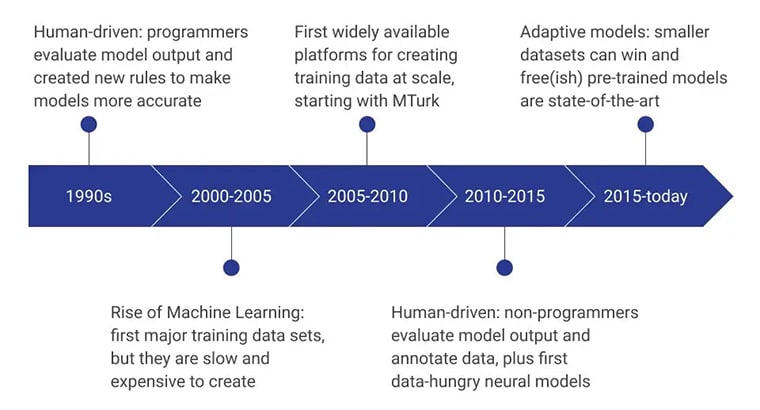
एआई प्रशिक्षण डेटा के प्रारंभिक चरण मानव प्रोग्रामर द्वारा संचालित किए गए थे जिन्होंने मॉडल को और अधिक कुशल बनाने वाले नए नियमों को लगातार तैयार करके मॉडल आउटपुट का मूल्यांकन किया। 2000 – 2005 की अवधि में, पहला प्रमुख डेटासेट बनाया गया था, और यह बेहद धीमी, संसाधन-निर्भर और महंगी प्रक्रिया थी। इसने प्रशिक्षण डेटासेट को बड़े पैमाने पर विकसित किया, और अमेज़ॅन के एमटर्क ने डेटा संग्रह के प्रति लोगों की धारणा को बदलने में महत्वपूर्ण भूमिका निभाई। साथ ही, मानव लेबलिंग और एनोटेशन भी शुरू हुआ।
अगले कुछ वर्षों में डेटा मॉडल बनाने और मूल्यांकन करने वाले गैर-प्रोग्रामर पर ध्यान केंद्रित किया गया। वर्तमान में, उन्नत प्रशिक्षण डेटा संग्रह विधियों का उपयोग करके विकसित पूर्व-प्रशिक्षित मॉडल पर ध्यान केंद्रित किया गया है।
गुणवत्ता से अधिक मात्रा
दिन में एआई प्रशिक्षण डेटासेट की अखंडता का आकलन करते समय, डेटा वैज्ञानिकों ने ध्यान केंद्रित किया एआई प्रशिक्षण डेटा मात्रा गुणवत्ता से अधिक।
उदाहरण के लिए, एक आम ग़लतफ़हमी थी कि बड़े डेटाबेस सटीक परिणाम देते हैं। डेटा की विशाल मात्रा को डेटा के मूल्य का एक अच्छा संकेतक माना जाता था। मात्रा डेटासेट के मूल्य को निर्धारित करने वाले प्राथमिक कारकों में से केवल एक है - डेटा गुणवत्ता की भूमिका को मान्यता दी गई थी।
जागरूकता है कि आँकड़े की गुणवत्ता डेटा पूर्णता, विश्वसनीयता, वैधता, उपलब्धता और समयबद्धता पर निर्भर वृद्धि हुई। सबसे महत्वपूर्ण बात यह है कि परियोजना के लिए डेटा उपयुक्तता एकत्रित डेटा की गुणवत्ता निर्धारित करती है।
खराब प्रशिक्षण डेटा के कारण शुरुआती एआई सिस्टम की सीमाएं
खराब प्रशिक्षण डेटा, उन्नत कंप्यूटिंग सिस्टम की कमी के साथ, प्रारंभिक एआई सिस्टम के कई अधूरे वादों के कारणों में से एक था।
गुणवत्ता प्रशिक्षण डेटा की कमी के कारण, एमएल समाधान तंत्रिका अनुसंधान के विकास को रोकने वाले दृश्य पैटर्न की सही पहचान नहीं कर सके। हालांकि कई शोधकर्ताओं ने बोली जाने वाली भाषा की मान्यता के वादे की पहचान की, भाषण डेटासेट की कमी के कारण वाक् पहचान उपकरणों का अनुसंधान या विकास सफल नहीं हो सका। उच्च अंत एआई उपकरण विकसित करने में एक और बड़ी बाधा कंप्यूटर की कम्प्यूटेशनल और भंडारण क्षमताओं की कमी थी।
गुणवत्ता प्रशिक्षण डेटा में बदलाव
जागरूकता में उल्लेखनीय बदलाव आया कि डेटासेट की गुणवत्ता मायने रखती है। एमएल प्रणाली के लिए मानव बुद्धि और निर्णय लेने की क्षमताओं की सटीक नकल करने के लिए, इसे उच्च-मात्रा, उच्च-गुणवत्ता वाले प्रशिक्षण डेटा पर पनपना होगा।
अपने एमएल डेटा को एक सर्वेक्षण के रूप में सोचें - जितना बड़ा होगा डेटा नमूना आकार, बेहतर भविष्यवाणी। यदि नमूना डेटा में सभी चर शामिल नहीं हैं, तो हो सकता है कि वह पैटर्न की पहचान न करे या गलत निष्कर्ष न निकाले।
एआई प्रौद्योगिकी में प्रगति और बेहतर प्रशिक्षण डेटा की आवश्यकता
 एआई प्रौद्योगिकी में प्रगति गुणवत्ता प्रशिक्षण डेटा की आवश्यकता को बढ़ा रही है।
एआई प्रौद्योगिकी में प्रगति गुणवत्ता प्रशिक्षण डेटा की आवश्यकता को बढ़ा रही है।यह समझ कि बेहतर प्रशिक्षण डेटा विश्वसनीय एमएल मॉडल की संभावना को बढ़ाता है, बेहतर डेटा संग्रह, एनोटेशन और लेबलिंग पद्धतियों को जन्म देता है। डेटा की गुणवत्ता और प्रासंगिकता ने AI मॉडल की गुणवत्ता को सीधे प्रभावित किया।
 एआई प्रौद्योगिकी में प्रगति गुणवत्ता प्रशिक्षण डेटा की आवश्यकता को बढ़ा रही है।
एआई प्रौद्योगिकी में प्रगति गुणवत्ता प्रशिक्षण डेटा की आवश्यकता को बढ़ा रही है।डेटा गुणवत्ता और सटीकता पर अधिक ध्यान
एमएल मॉडल के लिए सटीक परिणाम प्रदान करना शुरू करने के लिए, यह गुणवत्ता डेटासेट पर खिलाया जाता है जो पुनरावृत्त डेटा शोधन चरणों से गुजरता है।
उदाहरण के लिए, एक इंसान कुत्ते की एक विशिष्ट नस्ल को नस्ल से परिचित कराने के कुछ दिनों के भीतर - चित्रों, वीडियो या व्यक्तिगत रूप से पहचानने में सक्षम हो सकता है। मनुष्य अपने अनुभव और संबंधित जानकारी को याद रखने और आवश्यक होने पर इस ज्ञान को खींचने के लिए आकर्षित करता है। फिर भी, यह एक मशीन के लिए उतनी आसानी से काम नहीं करता है। कनेक्शन बनाने के लिए मशीन को स्पष्ट रूप से एनोटेट और लेबल की गई छवियों - सैकड़ों या हजारों - उस विशेष नस्ल और अन्य नस्लों के साथ खिलाया जाना चाहिए।
एक एआई मॉडल में प्रस्तुत जानकारी के साथ प्रशिक्षित जानकारी को सहसंबद्ध करके परिणाम की भविष्यवाणी करता है असली दुनिया. यदि प्रशिक्षण डेटा में प्रासंगिक जानकारी शामिल नहीं है, तो एल्गोरिथ्म बेकार हो जाता है।
विविध और प्रतिनिधि प्रशिक्षण डेटा का महत्व
बढ़ी हुई डेटा विविधता भी क्षमता को बढ़ाती है, पूर्वाग्रह को कम करती है और सभी परिदृश्यों के समान प्रतिनिधित्व को बढ़ावा देती है। यदि एआई मॉडल को समरूप डेटासेट का उपयोग करके प्रशिक्षित किया जाता है, तो आप सुनिश्चित हो सकते हैं कि नया एप्लिकेशन केवल एक विशिष्ट उद्देश्य के लिए काम करेगा और एक विशिष्ट आबादी की सेवा करेगा।एक डेटासेट किसी विशेष जनसंख्या, जाति, लिंग, पसंद और बौद्धिक राय के प्रति पक्षपाती हो सकता है, जिससे एक गलत मॉडल बन सकता है।
यह सुनिश्चित करना महत्वपूर्ण है कि संपूर्ण डेटा संग्रह प्रक्रिया प्रवाह, जिसमें विषय पूल, क्यूरेशन, एनोटेशन और लेबलिंग का चयन शामिल है, पर्याप्त रूप से विविध, संतुलित और जनसंख्या का प्रतिनिधि है।
 बढ़ी हुई डेटा विविधता भी क्षमता को बढ़ाती है, पूर्वाग्रह को कम करती है और सभी परिदृश्यों के समान प्रतिनिधित्व को बढ़ावा देती है। यदि एआई मॉडल को समरूप डेटासेट का उपयोग करके प्रशिक्षित किया जाता है, तो आप सुनिश्चित हो सकते हैं कि नया एप्लिकेशन केवल एक विशिष्ट उद्देश्य के लिए काम करेगा और एक विशिष्ट आबादी की सेवा करेगा।
बढ़ी हुई डेटा विविधता भी क्षमता को बढ़ाती है, पूर्वाग्रह को कम करती है और सभी परिदृश्यों के समान प्रतिनिधित्व को बढ़ावा देती है। यदि एआई मॉडल को समरूप डेटासेट का उपयोग करके प्रशिक्षित किया जाता है, तो आप सुनिश्चित हो सकते हैं कि नया एप्लिकेशन केवल एक विशिष्ट उद्देश्य के लिए काम करेगा और एक विशिष्ट आबादी की सेवा करेगा।एआई प्रशिक्षण डेटा का भविष्य
एआई मॉडल की भविष्य की सफलता एमएल एल्गोरिदम को प्रशिक्षित करने के लिए उपयोग किए जाने वाले प्रशिक्षण डेटा की गुणवत्ता और मात्रा पर निर्भर करती है। यह पहचानना महत्वपूर्ण है कि डेटा गुणवत्ता और मात्रा के बीच यह संबंध कार्य-विशिष्ट है और इसका कोई निश्चित उत्तर नहीं है।
अंततः, एक प्रशिक्षण डेटा सेट की पर्याप्तता को इसके द्वारा बनाए गए उद्देश्य के लिए मज़बूती से अच्छा प्रदर्शन करने की क्षमता से परिभाषित किया जाता है।
डेटा संग्रह और एनोटेशन तकनीकों में अग्रिम
चूंकि एमएल फेड डेटा के प्रति संवेदनशील है, इसलिए डेटा संग्रह और एनोटेशन नीतियों को कारगर बनाना महत्वपूर्ण है। डेटा संग्रह, क्यूरेशन, गलत बयानी, अपूर्ण माप, गलत सामग्री, डेटा दोहराव और गलत माप में त्रुटियां अपर्याप्त डेटा गुणवत्ता में योगदान करती हैं।
डेटा माइनिंग, वेब स्क्रैपिंग और डेटा निष्कर्षण के माध्यम से स्वचालित डेटा संग्रह तेजी से डेटा निर्माण का मार्ग प्रशस्त कर रहा है। इसके अतिरिक्त, प्री-पैकेज्ड डेटासेट त्वरित-फिक्स डेटा संग्रह तकनीक के रूप में कार्य करते हैं।
क्राउडसोर्सिंग डेटा संग्रह का एक और पथभ्रष्ट करने वाला तरीका है। जबकि डेटा की सत्यता की पुष्टि नहीं की जा सकती है, यह सार्वजनिक छवि एकत्र करने के लिए एक उत्कृष्ट उपकरण है। अंत में, विशेष डेटा संग्रह विशेषज्ञ विशिष्ट उद्देश्यों के लिए डेटा स्रोत भी प्रदान करते हैं।
प्रशिक्षण डेटा में नैतिक विचारों पर अधिक जोर
एआई में तेजी से प्रगति के साथ, कई नैतिक मुद्दे सामने आए हैं, खासकर प्रशिक्षण डेटा संग्रह में। प्रशिक्षण डेटा संग्रह में कुछ नैतिक विचारों में सूचित सहमति, पारदर्शिता, पूर्वाग्रह और डेटा गोपनीयता शामिल हैं।चूंकि डेटा में अब चेहरे की छवियों, उंगलियों के निशान, आवाज की रिकॉर्डिंग और अन्य महत्वपूर्ण बायोमेट्रिक डेटा से सब कुछ शामिल है, महंगे मुकदमों और प्रतिष्ठा को नुकसान से बचने के लिए कानूनी और नैतिक प्रथाओं का पालन सुनिश्चित करना गंभीर रूप से महत्वपूर्ण होता जा रहा है।
भविष्य में और भी बेहतर गुणवत्ता और विविध प्रशिक्षण डेटा की संभावना
की अपार संभावना है उच्च गुणवत्ता और विविध प्रशिक्षण डेटा भविष्य में। डेटा गुणवत्ता के बारे में जागरूकता और एआई समाधानों की गुणवत्ता मांगों को पूरा करने वाले डेटा प्रदाताओं की उपलब्धता के लिए धन्यवाद।
वर्तमान डेटा प्रदाता विविध डेटासेट की भारी मात्रा में नैतिक और कानूनी रूप से स्रोत के लिए अभूतपूर्व तकनीकों का उपयोग करने में माहिर हैं। उनके पास विभिन्न एमएल परियोजनाओं के लिए अनुकूलित डेटा को लेबल करने, एनोटेट करने और प्रस्तुत करने के लिए इन-हाउस टीमें भी हैं।
 एआई में तेजी से प्रगति के साथ, कई नैतिक मुद्दे सामने आए हैं, खासकर प्रशिक्षण डेटा संग्रह में। प्रशिक्षण डेटा संग्रह में कुछ नैतिक विचारों में सूचित सहमति, पारदर्शिता, पूर्वाग्रह और डेटा गोपनीयता शामिल हैं।
एआई में तेजी से प्रगति के साथ, कई नैतिक मुद्दे सामने आए हैं, खासकर प्रशिक्षण डेटा संग्रह में। प्रशिक्षण डेटा संग्रह में कुछ नैतिक विचारों में सूचित सहमति, पारदर्शिता, पूर्वाग्रह और डेटा गोपनीयता शामिल हैं।निष्कर्ष
डेटा और गुणवत्ता की तीव्र समझ के साथ विश्वसनीय विक्रेताओं के साथ साझेदारी करना महत्वपूर्ण है उच्च अंत एआई मॉडल विकसित करें. Shaip आपकी AI परियोजना की जरूरतों और लक्ष्यों को पूरा करने वाले अनुकूलित डेटा समाधान प्रदान करने में निपुण प्रमुख एनोटेशन कंपनी है। हमारे साथ भागीदार बनें और उन दक्षताओं, प्रतिबद्धता और सहयोग का अन्वेषण करें जिन्हें हम टेबल पर लाते हैं।


