
आर्टिफिशियल इंटेलिजेंस संगीत उद्योग में क्रांति ला रहा है, स्वचालित रचना, मास्टरिंग और प्रदर्शन उपकरण पेश कर रहा है। एआई एल्गोरिदम नवीन रचनाएँ उत्पन्न करते हैं, हिट की भविष्यवाणी करते हैं, और श्रोता के अनुभव को निजीकृत करते हैं, संगीत उत्पादन, वितरण और खपत को बदलते हैं। यह उभरती हुई तकनीक रोमांचक अवसर और चुनौतीपूर्ण नैतिक दुविधाएं दोनों प्रस्तुत करती है।
मशीन लर्निंग (एमएल) मॉडल को प्रभावी ढंग से कार्य करने के लिए प्रशिक्षण डेटा की आवश्यकता होती है, जैसे एक संगीतकार को सिम्फनी लिखने के लिए संगीत नोट्स की आवश्यकता होती है। संगीत की दुनिया में, जहां माधुर्य, लय और भावनाएं आपस में जुड़ी हुई हैं, गुणवत्ता प्रशिक्षण डेटा के महत्व को कम करके आंका नहीं जा सकता है। यह पूर्वानुमानित विश्लेषण, शैली वर्गीकरण, या स्वचालित ट्रांसक्रिप्शन के लिए मजबूत और सटीक संगीत एमएल मॉडल विकसित करने की रीढ़ है।
डेटा, एमएल मॉडल की जीवनधारा
मशीन लर्निंग स्वाभाविक रूप से डेटा-संचालित है। ये कम्प्यूटेशनल मॉडल डेटा से पैटर्न सीखते हैं, जिससे वे भविष्यवाणी या निर्णय लेने में सक्षम होते हैं। संगीत एमएल मॉडल के लिए, प्रशिक्षण डेटा अक्सर डिजीटल संगीत ट्रैक, गीत, मेटाडेटा या इन तत्वों के संयोजन में आता है। इस डेटा की गुणवत्ता, मात्रा और विविधता मॉडल की प्रभावशीलता पर महत्वपूर्ण प्रभाव डालती है।

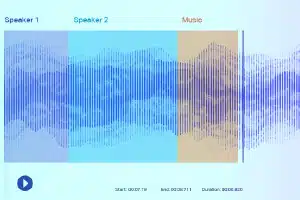
ध्वनि लेबलिंग
ध्वनि लेबलिंग के साथ, डेटा एनोटेटर्स को एक रिकॉर्डिंग दी जाती है और उन्हें सभी आवश्यक ध्वनियों को अलग करने और उन्हें लेबल करने की आवश्यकता होती है। उदाहरण के लिए, ये कुछ कीवर्ड या किसी विशिष्ट संगीत वाद्ययंत्र की ध्वनि हो सकते हैं।

संगीत वर्गीकरण
डेटा एनोटेटर इस प्रकार के ऑडियो एनोटेशन में शैलियों या उपकरणों को चिह्नित कर सकते हैं। संगीत पुस्तकालयों को व्यवस्थित करने और उपयोगकर्ता अनुशंसाओं को बेहतर बनाने के लिए संगीत वर्गीकरण बहुत उपयोगी है।

ध्वन्यात्मक स्तर विभाजन
अकापेल्ला गाने वाले व्यक्तियों की रिकॉर्डिंग के तरंग रूपों और स्पेक्ट्रोग्राम पर ध्वन्यात्मक खंडों का लेबल और वर्गीकरण।
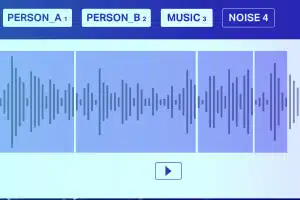
ध्वनि वर्गीकरण
मौन/सफ़ेद शोर को छोड़कर, एक ऑडियो फ़ाइल में आम तौर पर निम्नलिखित ध्वनि प्रकार होते हैं: भाषण, प्रलाप, संगीत और शोर। उच्च सटीकता के लिए संगीत नोट्स को सटीक रूप से एनोटेट करें।
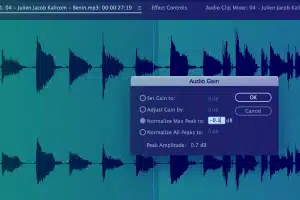
मेटाडेटा सूचना कैप्चरिंग
प्रारंभ समय, समाप्ति समय, खंड आईडी, ध्वनि स्तर, प्राथमिक ध्वनि प्रकार, भाषा कोड, स्पीकर आईडी, और अन्य प्रतिलेखन परंपराएं आदि जैसी महत्वपूर्ण जानकारी कैप्चर करें।


