
क्या आपने कभी सोचा है कि जब आप 'अरे सिरी' या 'एलेक्सा' कहते हैं तो चैटबॉट और वर्चुअल असिस्टेंट कैसे जाग जाते हैं? यह टेक्स्ट उच्चारण संग्रह या सॉफ़्टवेयर में एम्बेड किए गए शब्दों को ट्रिगर करता है जो सिस्टम को सक्रिय करता है जैसे ही यह प्रोग्राम किए गए वेक शब्द को सुनता है।
हालाँकि, ध्वनियाँ और उच्चारण डेटा बनाने की समग्र प्रक्रिया इतनी सरल नहीं है। यह एक ऐसी प्रक्रिया है जिसे वांछित परिणाम प्राप्त करने के लिए सही तकनीक के साथ किया जाना चाहिए। इसलिए, यह ब्लॉग अच्छे उच्चारण/ट्रिगर शब्द बनाने का मार्ग साझा करेगा जो आपके संवादी एआई के साथ सहजता से काम करते हैं।
कथन क्या हैं?
कृत्रिम रूप से बुद्धिमान मॉडल को सक्रिय करने के लिए उपयोग किए जाने वाले वाक्यांशों को वाक्यांशों या ट्रिगर शब्दों के रूप में संदर्भित किया जा सकता है। जब आपका एआई मॉडल अपने वेक शब्द का पता लगाता है, तो यह स्वचालित रूप से उपयोगकर्ता के अगले अनुरोध को रिकॉर्ड करना शुरू कर देता है और उपयुक्त कार्रवाई या उत्तर के साथ जवाब देता है।
वाक्करण गहरी शिक्षा की अवधारणा का उपयोग सॉफ्टवेयर को सिखाने के लिए करता है कि वेक शब्दों को कैसे पहचाना जाए। एक बार वेक वर्ड सॉफ्टवेयर को सक्रिय कर देता है, सिस्टम अनुरोध को कैप्चर करना, डिकोड करना और सर्विस करना शुरू कर देता है। उपयोग में नहीं होने पर, सिस्टम निष्क्रिय रूप से ट्रिगर शब्दों को सुनता रहता है।
आपके एआई सॉफ़्टवेयर के लिए सटीक परिणाम प्राप्त करने के लिए, हर इरादे के लिए अलग-अलग उच्चारणों की अधिकता को कैप्चर करना आवश्यक है। यह एआई मॉडल के लिए बेहतर प्रशिक्षण में मदद करता है।
[ये भी पढ़ें: क्या आप जानना चाहेंगे कि सिरी और एलेक्सा आपको कैसे समझते हैं??]
कथनों का भंडार बनाते समय याद रखने योग्य बातें
अब जब हम जानते हैं कि एआई मॉडल के लिए प्रशिक्षण महत्वपूर्ण है, तो अगली बात यह जानना है कि एआई मॉडल को उच्चारण कैसे प्रदान किया जाए। आमतौर पर, संवादात्मक एआई को प्रशिक्षित करने के लिए उच्चारणों का भंडार बनाया जाता है।
हालाँकि, कथनों के भंडार का निर्माण करते समय कई बातों का ध्यान रखना चाहिए। निम्नलिखित बातों पर विचार किया जाना चाहिए:
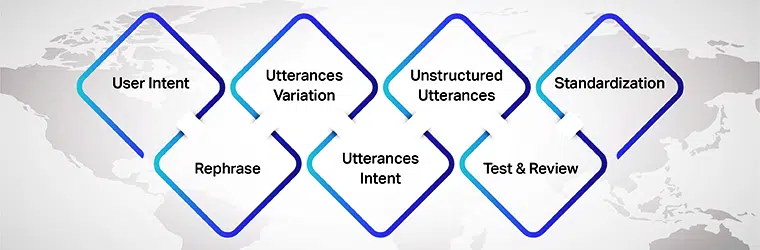
उपयोगकर्ता का इरादा
मुख्य रूप से अपने एआई मॉडल के लिए कथन तैयार करते समय, सुनिश्चित करें कि आप उस उपयोगकर्ता के इरादे को समझते हैं जिसके लिए आप डेटासेट विकसित कर रहे हैं। एआई मॉडल के साथ बातचीत करते समय आपको अलग-अलग उच्चारणों का पता लगाना होगा जो उपयोगकर्ता दर्ज कर सकते हैं।
कथनों का रूपांतर
भिन्नताएं इस प्रक्रिया का एक अनिवार्य हिस्सा हैं, क्योंकि प्रत्येक इंटेंट के लिए जितनी अधिक विविधताएं होंगी, आपको उतने ही बेहतर परिणाम प्राप्त होंगे। इसलिए, सुनिश्चित करें कि आप उपयोगकर्ता के कथनों के अनेक रूप बनाते हैं। आप इसे करके कर सकते हैं
- एक ही वाक्य के लिए छोटे, मध्यम और बड़े वाक्य बनाना।
- शब्दों और वाक्यों की लंबाई बदलना।
- अनोखे शब्दों का प्रयोग।
- वाक्यों का बहुवचन बनाना।
- व्याकरण मिलाना।



