हमारी डिजिटल दुनिया में, व्यवसाय प्रतिदिन टन डेटा संसाधित करते हैं। डेटा संगठन को चालू रखता है और बेहतर जानकारी वाले निर्णय लेने में मदद करता है। ईमेल, पोर्टल, चालान, रसीदें, आवेदन, प्रस्ताव, दावे, और अधिक जैसे विभिन्न स्रोतों से संगठन में प्रवेश करने वाले दस्तावेज़ों के लिए नए दस्तावेज़ बनाने वाले कर्मचारियों से व्यवसाय दस्तावेज़ों से भर गए हैं।
जब तक कोई इन दस्तावेज़ों की समीक्षा नहीं करता है, तब तक यह जानने का कोई तरीका नहीं है कि कोई विशेष दस्तावेज़ किस बारे में है या इसे संसाधित करने का सबसे अच्छा तरीका है। हालाँकि, प्रत्येक दस्तावेज़ को मैन्युअल रूप से संसाधित करना यह जानने के लिए कि इसे कहाँ और कैसे संग्रहीत किया जाना चाहिए, मुश्किल है।
आइए हम दस्तावेज़ वर्गीकरण का अन्वेषण करें, समझें कि व्यवसाय के लिए दस्तावेज़ वर्गीकरण क्यों महत्वपूर्ण है, और अध्ययन करें कि कंप्यूटर विज़न, प्राकृतिक भाषा प्रसंस्करण और ऑप्टिकल कैरेक्टर रिकॉग्निशन दस्तावेज़ वर्गीकरण या दस्तावेज़ प्रसंस्करण में कैसे भूमिका निभाते हैं।
दस्तावेज़ वर्गीकरण क्या है?
मैनुअल दस्तावेज़ वर्गीकरण कार्य कई व्यवसायों के लिए एक बड़ी अड़चन हो सकते हैं क्योंकि वे समय लेने वाले, त्रुटि-प्रवण और संसाधन-उपभोक्ता हैं। जब एनएलपी और एमएल पर आधारित स्वचालित वर्गीकरण मॉडल का उपयोग किया जाता है, तो दस्तावेज़ में पाठ स्वचालित रूप से पहचाना जाता है, टैग किया जाता है और वर्गीकृत किया जाता है।
दस्तावेज़ वर्गीकरण कार्य आम तौर पर दो वर्गीकरणों पर आधारित होते हैं: पाठ और दृश्य। टेक्स्ट वर्गीकरण सामग्री की शैली, थीम या प्रकार पर आधारित है। पाठ की अवधारणा, भावनाओं और संदर्भ को समझने के लिए प्राकृतिक भाषा प्रसंस्करण का उपयोग किया जाता है। कंप्यूटर दृष्टि और छवि पहचान प्रणाली का उपयोग करके दस्तावेज़ में मौजूद दृश्य संरचनात्मक तत्वों के आधार पर दृश्य वर्गीकरण किया जाता है।
व्यवसायों को दस्तावेज़ वर्गीकरण की आवश्यकता क्यों है?

प्रत्येक व्यवसाय, चाहे वह बड़ा हो या छोटा, को अपने रोजमर्रा के कार्यों को प्रबंधित करने के लिए दस्तावेज़ीकरण से निपटना पड़ता है। चूंकि प्रत्येक दस्तावेज़ को मैन्युअल रूप से संसाधित करना असंभव है, इसलिए स्वचालित दस्तावेज़ वर्गीकरण प्रणाली को नियोजित करना आवश्यक है। दस्तावेज़ वर्गीकरण प्रणाली व्यवसायों को सामग्री व्यवस्थित करने और इसे किसी भी समय उपलब्ध कराने की अनुमति देती है।
दस्तावेज़ वर्गीकरण में अस्पतालों से लेकर व्यवसायों तक, विभिन्न उद्योगों में कई उपयोग के मामले हैं।
- यह व्यवसायों को दस्तावेज़ प्रबंधन और प्रसंस्करण को स्वचालित करने में मदद करता है।
- दस्तावेज़ वर्गीकरण एक सांसारिक और दोहराव वाला कार्य है, प्रक्रिया को स्वचालित करने से प्रसंस्करण त्रुटियां कम हो जाती हैं और टर्नअराउंड समय में सुधार होता है।
- दस्तावेजों के स्वचालन से दक्षता, विश्वसनीयता और मापनीयता में भी सुधार होता है।
दस्तावेज़ वर्गीकरण बनाम। पाठ वर्गीकरण
पाठ वर्गीकरण और दस्तावेज़ वर्गीकरण को कभी-कभी एक दूसरे के स्थान पर उपयोग किया जाता है। हालांकि दोनों के बीच बहुत मामूली अंतर है, यह जानना महत्वपूर्ण है कि वे कैसे भिन्न होते हैं।
पाठ का वर्गीकरण टेक्स्ट-आधारित दस्तावेज़ों में टेक्स्ट का विश्लेषण करने के लिए तकनीकों को नियोजित करने के बारे में है। पाठ को विभिन्न स्तरों पर वर्गीकृत किया जा सकता है, जैसे
| वाक्य स्तर | उपवाक्य स्तर |
|---|---|
| पाठ वर्गीकरण एक वाक्य में जानकारी पर आधारित है। | उप-वाक्य स्तर वाक्यों के भीतर से उप-अभिव्यक्तियाँ खींचता है। |
| पैराग्राफ स्तर | दस्तावेज़ स्तर |
|---|---|
| एक पैराग्राफ से मुख्य या सबसे महत्वपूर्ण जानकारी निकालता है। | संपूर्ण दस्तावेज़ से महत्वपूर्ण जानकारी निकालें। |
पाठ वर्गीकरण दस्तावेज़ वर्गीकरण का एक उपसमुच्चय है जो किसी दिए गए दस्तावेज़ में पाठ को पूरी तरह से वर्गीकृत करने से संबंधित है। जबकि पाठ वर्गीकरण केवल पाठ से संबंधित है, दस्तावेज़ वर्गीकरण पाठ्य और दृश्य दोनों है। पाठ वर्गीकरण में, केवल पाठ का उपयोग वर्गीकृत करने के लिए किया जाता है, जबकि दस्तावेज़ वर्गीकरण में, संपूर्ण दस्तावेज़ को संदर्भ के लिए उपयोग किया जा सकता है।
दस्तावेज़ वर्गीकरण कैसे काम करता है?
दस्तावेज़ वर्गीकरण दो विधियों का उपयोग करके किया जा सकता है: मैनुअल और स्वचालित। मैनुअल वर्गीकरण में, एक मानव उपयोगकर्ता को दस्तावेज़ों की समीक्षा करनी चाहिए, अवधारणाओं के बीच संबंधों का पता लगाना चाहिए और तदनुसार वर्गीकृत करना चाहिए। स्वचालित दस्तावेज़ वर्गीकरण में, मशीन लर्निंग और डीप लर्निंग तकनीकों का उपयोग किया जाता है। आइए विभिन्न प्रकार के दस्तावेज़ों को व्यावसायिक प्रक्रियाओं को समझकर दस्तावेज़ वर्गीकरण विधियों को जानें।
संरचित दस्तावेज़
एक दस्तावेज़ में सुसंगत क्रमांकन और फोंट के साथ अच्छी तरह से स्वरूपित डेटा होता है। दस्तावेज़ का लेआउट भी सुसंगत है और इसमें कोई विचलन नहीं है। ऐसे संरचित दस्तावेजों के लिए बिल्डिंग वर्गीकरण उपकरण आसान और अनुमानित है।
असंरचित दस्तावेज
एक असंरचित दस्तावेज़ में एक गैर-संरचित या खुले प्रारूप में सामग्री प्रस्तुत की जाती है। उदाहरणों में पत्र, अनुबंध और आदेश शामिल हैं। चूंकि वे असंगत हैं, इसलिए महत्वपूर्ण जानकारी का पता लगाना चुनौतीपूर्ण हो जाता है।

दस्तावेज़ वर्गीकरण तकनीक?
स्वचालित दस्तावेज़ वर्गीकरण वर्गीकरण प्रक्रिया को सरल, स्वचालित और तेज़ करने के लिए मशीन लर्निंग और प्राकृतिक भाषा प्रसंस्करण तकनीकों का उपयोग करता है। मशीन लर्निंग दस्तावेज़ वर्गीकरण को कम बोझिल, तेज़, अधिक सटीक, स्केलेबल और निष्पक्ष बनाता है।
दस्तावेज़ वर्गीकरण तीन तकनीकों का उपयोग करके किया जा सकता है। वे हैं
नियम-आधारित तकनीक
नियम-आधारित तकनीक भाषाई प्रतिमानों और नियमों पर आधारित है जो मॉडल को निर्देश प्रदान करते हैं। पाठ को टैग करने के लिए मॉडल को भाषा पैटर्न, आकृति विज्ञान, वाक्य रचना, शब्दार्थ और अन्य की पहचान करने के लिए प्रशिक्षित किया जाता है। इस तकनीक में लगातार सुधार किया जा सकता है, नए नियम जोड़े जा सकते हैं और सटीक अंतर्दृष्टि निकालने के लिए सुधार किया जा सकता है। हालांकि, यह तकनीक समय लेने वाली, स्केलेबल और जटिल हो सकती है।
पर्यवेक्षित अध्ययन
पर्यवेक्षित शिक्षण में टैग के एक सेट को परिभाषित किया गया है, और कई पाठों को मैन्युअल रूप से टैग किया गया है ताकि मशीन लर्निंग सिस्टम सटीक भविष्यवाणी करना सीख सके। एल्गोरिथ्म को टैग किए गए दस्तावेज़ों के एक सेट पर मैन्युअल रूप से प्रशिक्षित किया जाता है। आप सिस्टम में जितना अधिक डेटा फीड करेंगे, परिणाम उतने ही बेहतर होंगे। उदाहरण के लिए, यदि पाठ कहता है, 'सेवा सस्ती थी,' टैग 'मूल्य निर्धारण' के अंतर्गत होना चाहिए। एक बार मॉडल का प्रशिक्षण पूरा हो जाने के बाद, यह स्वचालित रूप से अनदेखे दस्तावेज़ों की भविष्यवाणी कर सकता है।
अनसुनी हुई पढ़ाई
अप्रशिक्षित शिक्षण में, समान दस्तावेजों को अलग-अलग समूहों में बांटा जाता है। इस सीखने के लिए किसी पूर्व ज्ञान की आवश्यकता नहीं है। दस्तावेजों को फोंट, थीम, टेम्प्लेट और बहुत कुछ के आधार पर वर्गीकृत किया गया है। यदि नियम पूर्व-परिभाषित, संशोधित और पूर्ण हैं, तो यह मॉडल सटीकता के साथ वर्गीकरण प्रदान कर सकता है।
दस्तावेज़ वर्गीकरण प्रक्रिया
एक स्वचालित दस्तावेज़ वर्गीकरण एल्गोरिथ्म के निर्माण में गहन शिक्षण और मशीन शिक्षण कार्यप्रवाह शामिल हैं।
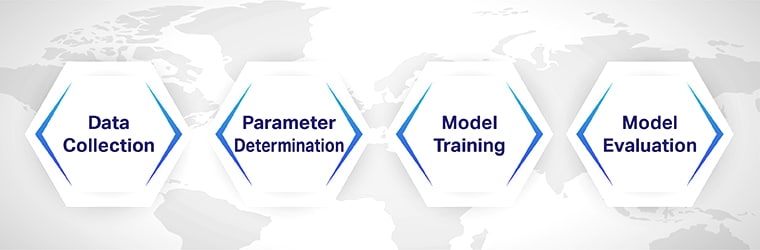
चरण 1: डेटा संग्रह
डेटा संग्रहण प्रशिक्षण दस्तावेज़ वर्गीकरण एल्गोरिदम में शायद सबसे महत्वपूर्ण कदम है। विभिन्न श्रेणियों से दस्तावेजों को इकट्ठा करना आवश्यक है ताकि एल्गोरिद्म उन्हें वर्गीकृत करना सीख सके।
उदाहरण के लिए, यदि आपके मॉडल को पांच अलग-अलग श्रेणियों में वर्गीकृत करने की आवश्यकता है, तो आपके पास एक डेटासेट होना चाहिए जिसमें प्रति श्रेणी न्यूनतम 300 दस्तावेज़ हों।
साथ ही, सुनिश्चित करें कि आप प्रशिक्षण के लिए जिस डेटासेट का उपयोग कर रहे हैं, वह सही तरीके से टैग किया गया है। यदि डेटासेट गलत है, तो आपके द्वारा बनाया गया मॉडल समस्याओं से भरा होगा।
चरण 2: पैरामीटर निर्धारण
मॉडल को प्रशिक्षित करने से पहले, आपको मशीन लर्निंग मॉडल को प्रशिक्षित करने के लिए मापदंडों का निर्धारण करना चाहिए। इस स्तर पर आप जो मेट्रिक्स परिभाषित करते हैं, उन्हें मॉडल की भविष्यवाणियों में अधिक सटीक और विश्वसनीय बनाने के लिए संशोधित किया जा सकता है।
चरण 3: मॉडल प्रशिक्षण
पैरामीटर सेट करने के बाद, मॉडल को प्रशिक्षित करना होगा। यदि आप मॉडल विकास के साथ अभी शुरुआत कर रहे हैं, तो आप प्रशिक्षण और परीक्षण उद्देश्यों के लिए ओपन-सोर्स डेटासेट का उपयोग करने का प्रयास कर सकते हैं।
यदि मॉडल आमतौर पर मशीन लर्निंग एल्गोरिदम के साथ काम करता है, तो आप एल्गोरिथम के तर्क के आधार पर मॉडल को आयात कर सकते हैं या कोडिंग कर सकते हैं।
चरण 4: मॉडल मूल्यांकन
प्रशिक्षण के बाद मॉडल का मूल्यांकन इसकी प्रभावशीलता और सटीकता को बढ़ाने के लिए आवश्यक है। डेटासेट को दो व्यापक वर्गों में विभाजित करके प्रारंभ करें, एक प्रशिक्षण के लिए और दूसरा परीक्षण के लिए। परीक्षण और मूल्यांकन के लिए मॉडल के प्रशिक्षण के लिए 70% डेटासेट और शेष 30% का उपयोग करें।
वास्तविक जीवन में उपयोग के मामले
कई व्यावसायिक समस्याओं के समाधान के लिए दस्तावेज़ वर्गीकरण का उपयोग किया जा रहा है। हालांकि अधिकांश उपयोग के मामले वर्गीकरण कार्य नहीं हैं, एल्गोरिथ्म खुद को कई वास्तविक जीवन की समस्याओं को हल करने के लिए नियोजित पाता है।
स्पैम का पता लगाना
अवांछित स्पैम का पता लगाने के लिए दस्तावेज़ वर्गीकरण, विशेष रूप से टेक्स्ट वर्गीकरण का उपयोग किया जाता है। मॉडल को स्पैम वाक्यांशों और उनकी आवृत्ति का पता लगाने के लिए प्रशिक्षित किया जाता है ताकि यह निर्धारित किया जा सके कि संदेश स्पैम है या नहीं। उदाहरण के लिए, Google का जीमेल स्पैम डिटेक्टर जंक संदेशों में अक्सर आने वाले शब्दों का पता लगाने और मेल को सही फ़ोल्डर में छोड़ने के लिए प्राकृतिक भाषा प्रसंस्करण तकनीक का उपयोग करता है।
भावनाओं का विश्लेषण
सामाजिक सुनने के माध्यम से भावना विश्लेषण व्यवसायों को अपने ग्राहकों, उनकी राय और उनकी समीक्षाओं को समझने में सहायता करता है। समीक्षाओं, फीडबैक और शिकायतों को वर्गीकृत करके और उनकी भावनात्मक प्रकृति के आधार पर उन्हें वर्गीकृत करके, एनएलपी-आधारित मॉडल भावना विश्लेषण में मदद करते हैं। मॉडल को उन शब्दों को निकालने के लिए प्रशिक्षित किया जाता है जो सकारात्मक या नकारात्मक अर्थों को दर्शाते हैं या हैं।
टिकट या प्राथमिकता वर्गीकरण
किसी भी व्यवसाय के ग्राहक सेवा विभाग को कई सेवा अनुरोध और टिकट मिलते हैं। एक स्वचालित दस्तावेज़ वर्गीकरण उपकरण भारी मात्रा में टिकटों के माध्यम से उतारा जा सकता है। एनएलपी का उपयोग करते हुए, प्राथमिकता वाले टिकटों को सही विभाग में भेजा जा सकता है। यह रिज़ॉल्यूशन, प्रोसेसिंग और सर्विसिंग की गति में काफी सुधार करता है।
वस्तु मान्यता
स्वचालित दस्तावेज़ वर्गीकरण का उपयोग दस्तावेजों में बड़ी मात्रा में दृश्य डेटा को श्रेणियों के अनुसार वर्गीकृत करके संसाधित करने के लिए भी किया जाता है। वस्तु पहचान आमतौर पर उत्पादों को वर्गीकृत करने के लिए ईकामर्स या विनिर्माण इकाइयों में उपयोग की जाती है।
एआई द्वारा संचालित दस्तावेज़ वर्गीकरण के साथ आरंभ करना
दस्तावेज़ों में व्यवसाय के कामकाज के लिए महत्वपूर्ण डेटा होता है। दस्तावेजों में मूल्यवान अंतर्दृष्टि होती है जो किसी संगठन के संचालन, सेवाओं और विकास लक्ष्यों को आगे बढ़ाती है।
हालाँकि, दस्तावेजों को वर्गीकृत करना एक कठिन लेकिन आवश्यक कार्य है। चूंकि दस्तावेज़ वर्गीकरण एक चुनौती है, विशेष रूप से यदि मात्रा अपेक्षाकृत अधिक है, तो एक स्वचालित दस्तावेज़ वर्गीकरण प्रणाली होना आवश्यक है।
मशीन लर्निंग एल्गोरिदम द्वारा प्रशिक्षित एआई-आधारित दस्तावेज़ वर्गीकरण मॉडल कुशल, लागत प्रभावी, त्रुटि-मुक्त और सटीक है। लेकिन प्रक्रिया तभी शुरू हो सकती है जब आपके द्वारा बनाए जा रहे मॉडल को गुणवत्ता और सटीक रूप से टैग किए गए डेटासेट पर प्रशिक्षित किया जाए।
शेप आपके लिए लाता है पूर्व-टैग किए गए डेटासेट जो सटीक वर्गीकरण मॉडल विकसित करने में सहायता करते हैं। हमसे संपर्क करें और अपने दस्तावेज़ वर्गीकरण टूल के साथ तुरंत आरंभ करें।