
बड़े भाषा मॉडल ने हाल ही में अत्यधिक सक्षम उपयोग मामले के बाद बड़े पैमाने पर प्रमुखता प्राप्त की है चैटजीपीटी रातोंरात सफलता बन गई है। चैटजीपीटी और अन्य चैटबॉट्स की सफलता को देखते हुए, बड़ी संख्या में लोग और संगठन उस तकनीक की खोज में रुचि रखते हैं जो इस तरह के सॉफ्टवेयर को शक्ति प्रदान करती है।
बड़े भाषा मॉडल इस सॉफ़्टवेयर के पीछे की रीढ़ हैं जो विभिन्न प्राकृतिक भाषा प्रसंस्करण अनुप्रयोगों जैसे मशीन अनुवाद, वाक् पहचान, प्रश्न उत्तर और पाठ सारांश के काम को सक्षम बनाता है। आइए हम एलएलएम के बारे में अधिक जानें और सर्वोत्तम परिणामों के लिए आप इसे कैसे अनुकूलित कर सकते हैं।
बड़े भाषा मॉडल या चैटजीपीटी क्या हैं?
बड़े भाषा मॉडल मशीन लर्निंग मॉडल हैं जो एनएलपी अनुप्रयोगों को शक्ति देने के लिए कृत्रिम तंत्रिका नेटवर्क और डेटा के बड़े साइलो का लाभ उठाते हैं। बड़ी मात्रा में डेटा पर प्रशिक्षण के बाद, एलएलएम प्राकृतिक भाषा की विभिन्न जटिलताओं को पकड़ने की क्षमता प्राप्त करता है, जिसका आगे उपयोग किया जाता है:
- नए पाठ का सृजन
- लेखों और गद्यांशों का सारांश
- डेटा का निष्कर्षण
- पाठ को पुनर्लेखन या व्याख्या करना
- डेटा का वर्गीकरण
LLM के कुछ लोकप्रिय उदाहरण BERT, चैट GPT-3 और XLNet हैं। इन मॉडलों को लाखों-करोड़ों पाठों पर प्रशिक्षित किया जाता है और ये सभी प्रकार के विशिष्ट उपयोगकर्ता प्रश्नों के सार्थक समाधान प्रदान कर सकते हैं।
बड़े भाषा मॉडल के लोकप्रिय उपयोग के मामले
एलएलएम के कुछ शीर्ष और सबसे प्रचलित उपयोग मामले यहां दिए गए हैं:
टेक्स्ट जनरेशन
बड़े भाषा मॉडल आर्टिफिशियल इंटेलिजेंस और कम्प्यूटेशनल भाषाविज्ञान ज्ञान का उपयोग स्वचालित रूप से प्राकृतिक भाषा पाठ उत्पन्न करने और लेख, गीत लिखने या यहां तक कि उपयोगकर्ताओं के साथ चैट करने जैसी विभिन्न संप्रेषणीय उपयोगकर्ता आवश्यकताओं को पूरा करने के लिए करते हैं।
यंत्र अनुवाद
एलएलएम का उपयोग किसी भी दो भाषाओं के बीच पाठ का अनुवाद करने के लिए भी किया जा सकता है। स्रोत और लक्ष्य भाषाओं की भाषा संरचना सीखने के लिए मॉडल गहन शिक्षण एल्गोरिदम का लाभ उठाते हैं, जैसे आवर्तक तंत्रिका नेटवर्क। तदनुसार, उनका उपयोग स्रोत पाठ को लक्ष्य भाषा में अनुवाद करने के लिए किया जाता है।
निर्माण सामग्री
एलएलएम ने अब मशीनों के लिए सुसंगत और तार्किक सामग्री बनाना संभव बना दिया है जिसका उपयोग ब्लॉग पोस्ट, लेख और सामग्री के अन्य रूपों को उत्पन्न करने के लिए किया जा सकता है। उपयोगकर्ताओं के लिए एक अद्वितीय और पठनीय प्रारूप में सामग्री को समझने और संरचना करने के लिए मॉडल अपने व्यापक गहन शिक्षण ज्ञान का उपयोग करते हैं।
भावनाओं का विश्लेषण
यह बड़े भाषा मॉडल का एक रोमांचक उपयोग मामला है जिसमें लेबल किए गए पाठ में भावनात्मक राज्यों और भावनाओं को पहचानने और वर्गीकृत करने के लिए मॉडल को प्रशिक्षित किया जाता है। सॉफ्टवेयर सकारात्मकता, नकारात्मकता, तटस्थता और अन्य जटिल भावनाओं जैसी भावनाओं का पता लगा सकता है जो विभिन्न उत्पादों और सेवाओं के बारे में ग्राहकों की राय और समीक्षाओं में अंतर्दृष्टि प्राप्त करने में मदद कर सकता है।
पाठ की समझ, सारांश और वर्गीकरण
एलएलएम टेक्स्ट और उसके संदर्भ को समझने के लिए एआई सॉफ्टवेयर के लिए एक व्यावहारिक ढांचा प्रदान करते हैं। डेटा के बड़े ढेर को समझने और उसका विश्लेषण करने के लिए मॉडल को प्रशिक्षित करके, एलएलएम एआई मॉडल को विभिन्न रूपों और पैटर्न में पाठ को समझने, सारांशित करने और यहां तक कि वर्गीकृत करने में सक्षम बनाता है।
प्रश्न उत्तर देना
बड़े भाषा मॉडल क्यूए सिस्टम को उपयोगकर्ता की प्राकृतिक भाषा क्वेरी का सटीक रूप से पता लगाने और प्रतिक्रिया देने में सक्षम बनाते हैं। इस उपयोग मामले के सबसे लोकप्रिय अनुप्रयोगों में से एक चैटजीपीटी और बीईआरटी है, जो एक प्रश्न के संदर्भ का विश्लेषण करते हैं और उपयोगकर्ता के प्रश्नों के प्रासंगिक उत्तर खोजने के लिए ग्रंथों के एक बड़े कोष के माध्यम से खोज करते हैं।
[ये भी पढ़ें: भाषा प्रसंस्करण का भविष्य: बड़े भाषा मॉडल और उदाहरण ]

एलएलएम को सफल बनाने के लिए 3 आवश्यक शर्तें
दक्षता बढ़ाने और अपने बड़े भाषा मॉडल को सफल बनाने के लिए निम्नलिखित तीन शर्तों को सटीक रूप से पूरा किया जाना चाहिए:
मॉडल प्रशिक्षण के लिए भारी मात्रा में डेटा की उपस्थिति
एलएलएम को कुशल और इष्टतम परिणाम प्रदान करने वाले मॉडलों को प्रशिक्षित करने के लिए बड़ी मात्रा में डेटा की आवश्यकता होती है। विशिष्ट विधियाँ हैं, जैसे ट्रांसफर लर्निंग और स्व-पर्यवेक्षित पूर्व-प्रशिक्षण, जो एलएलएम अपने प्रदर्शन और सटीकता को बेहतर बनाने के लिए लाभ उठाते हैं।
मॉडलों को जटिल पैटर्न की सुविधा के लिए न्यूरॉन्स की परतें बनाना
एक बड़े भाषा मॉडल में डेटा में जटिल पैटर्न को समझने के लिए विशेष रूप से प्रशिक्षित न्यूरॉन्स की विभिन्न परतें शामिल होनी चाहिए। गहरी परतों में न्यूरॉन्स उथली परतों की तुलना में जटिल पैटर्न को बेहतर ढंग से समझ सकते हैं। मॉडल शब्दों के बीच जुड़ाव, एक साथ दिखाई देने वाले विषयों और भाषण के कुछ हिस्सों के बीच के संबंध को सीख सकता है।
उपयोगकर्ता-विशिष्ट कार्यों के लिए एलएलएम का अनुकूलन
परतों, न्यूरॉन्स और सक्रियण कार्यों की संख्या को बदलकर एलएलएम को विशिष्ट कार्यों के लिए ट्वीक किया जा सकता है। उदाहरण के लिए, एक मॉडल जो वाक्य में निम्नलिखित शब्द की भविष्यवाणी करता है, आमतौर पर स्क्रैच से नए वाक्य बनाने के लिए डिज़ाइन किए गए मॉडल की तुलना में कम परतों और न्यूरॉन्स का उपयोग करता है।
बड़े भाषा मॉडल के लोकप्रिय उदाहरण
विभिन्न उद्योगों में व्यापक रूप से उपयोग किए जाने वाले एलएलएम के कुछ प्रमुख उदाहरण यहां दिए गए हैं:
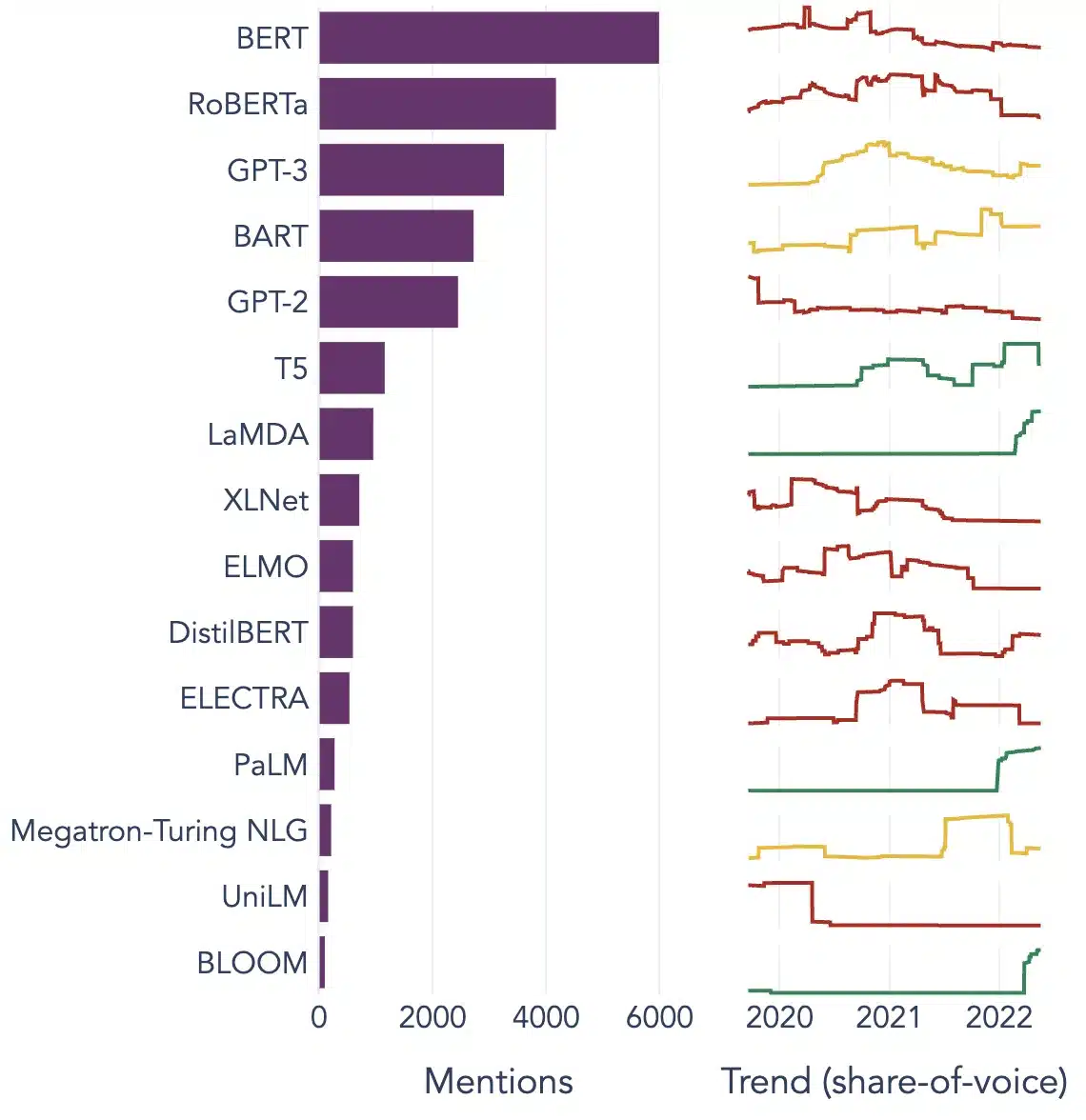
छवि स्रोत: डेटा साइंस की ओर
निष्कर्ष
एलएलएम मजबूत और सटीक भाषा समझने की क्षमता और समाधान प्रदान करके एनएलपी में क्रांति लाने की क्षमता रखता है जो एक सहज उपयोगकर्ता अनुभव प्रदान करता है। हालांकि, एलएलएम को अधिक कुशल बनाने के लिए, डेवलपर्स को अधिक सटीक परिणाम उत्पन्न करने और अत्यधिक प्रभावी एआई मॉडल तैयार करने के लिए उच्च गुणवत्ता वाले भाषण डेटा का लाभ उठाना चाहिए।
शैप प्रमुख एआई तकनीकी समाधानों में से एक है जो 50 से अधिक भाषाओं और कई प्रारूपों में स्पीच डेटा की एक विस्तृत श्रृंखला पेश करता है। एलएलएम के बारे में और जानें और अपनी परियोजनाओं पर मार्गदर्शन लें जहाज विशेषज्ञ आज.


