इंटरनेट ने दुनिया में किसी भी चीज़ के बारे में अपनी राय, विचार और सुझाव स्वतंत्र रूप से व्यक्त करने वाले लोगों के लिए दरवाजे खोल दिए हैं सोशल मीडिया, वेबसाइटें, और ब्लॉग। अपनी राय व्यक्त करने के अलावा, लोग (ग्राहक) दूसरों के खरीद निर्णयों को भी प्रभावित कर रहे हैं। भावना, चाहे नकारात्मक हो या सकारात्मक, किसी भी व्यवसाय या ब्रांड के लिए अपने उत्पादों या सेवाओं की बिक्री से संबंधित महत्वपूर्ण है।
व्यवसायों को व्यावसायिक उपयोग के लिए टिप्पणियों को माइन करने में मदद करना है प्राकृतिक भाषा संसाधन. हर चार व्यवसायों में से एक अपने व्यावसायिक निर्णयों को शक्ति प्रदान करने के लिए अगले वर्ष के भीतर एनएलपी प्रौद्योगिकी को लागू करने की योजना है। भावना विश्लेषण का उपयोग करते हुए, एनएलपी व्यवसायों को कच्चे और असंरचित डेटा से व्याख्यात्मक अंतर्दृष्टि प्राप्त करने में सहायता करता है।
राय खनन या भावना विश्लेषण एनएलपी की एक तकनीक है जिसका उपयोग सटीक भाव की पहचान करने के लिए किया जाता है – सकारात्मक, नकारात्मक या तटस्थ - टिप्पणियों और प्रतिक्रिया से जुड़े। एनएलपी की मदद से, कीवर्ड में निहित सकारात्मक या नकारात्मक शब्दों को निर्धारित करने के लिए टिप्पणियों में कीवर्ड का विश्लेषण किया जाता है।
भावनाओं को एक स्केलिंग सिस्टम पर स्कोर किया जाता है जो पाठ के एक टुकड़े में भावनाओं को भावना स्कोर प्रदान करता है (पाठ को सकारात्मक या नकारात्मक के रूप में निर्धारित करना)।
बहुभाषी भावना विश्लेषण क्या है?

, नाम से पता चलता है बहुभाषी भावना विश्लेषण एक से अधिक भाषाओं के लिए सेंटीमेंट स्कोर करने की तकनीक है। हालाँकि, यह उतना सरल नहीं है। हमारी संस्कृति, भाषा और अनुभव हमारे खरीद व्यवहार और भावनाओं को बहुत प्रभावित करते हैं। उपयोगकर्ता की भाषा, संदर्भ और संस्कृति की अच्छी समझ के बिना उपयोगकर्ता के इरादों, भावनाओं और व्याख्याओं को सटीक रूप से समझना असंभव है।
जबकि स्वचालन हमारी कई आधुनिक समस्याओं का उत्तर है, मशीन अनुवाद सॉफ्टवेयर टिप्पणियों में भाषा, बोलचाल, सूक्ष्मता और सांस्कृतिक संदर्भों की बारीकियों को लेने में सक्षम नहीं होगा और उत्पाद की समीक्षा यह अनुवाद कर रहा है। एमएल टूल आपको अनुवाद दे सकता है, लेकिन यह उपयोगी नहीं हो सकता है। यही कारण है कि बहुभाषी भावना विश्लेषण की आवश्यकता है।
बहुभाषी मनोभाव विश्लेषण की आवश्यकता क्यों है?
अधिकांश व्यवसाय अंग्रेजी का उपयोग अपने संचार माध्यम के रूप में करते हैं, लेकिन इसका उपयोग दुनिया भर के अधिकांश उपभोक्ताओं द्वारा नहीं किया जाता है।
एथनोलॉग के अनुसार, दुनिया की लगभग 13% आबादी अंग्रेजी बोलती है। इसके अतिरिक्त, ब्रिटिश काउंसिल का कहना है कि दुनिया की लगभग 25% आबादी को अंग्रेजी की अच्छी समझ है। इन नंबरों की मानें तो उपभोक्ताओं का एक बड़ा हिस्सा आपस में बातचीत करता है और बिजनेस अंग्रेजी के अलावा किसी दूसरी भाषा में करता है।
यदि व्यवसायों का मुख्य उद्देश्य अपने ग्राहक आधार को अक्षुण्ण रखना और नए ग्राहकों को आकर्षित करना है, तो उसे अपने ग्राहकों की राय को गहराई से समझना होगा। देशी भाषा. मैन्युअल रूप से प्रत्येक टिप्पणी की समीक्षा करना या उन्हें अंग्रेजी में अनुवाद करना एक बोझिल प्रक्रिया है जो प्रभावी परिणाम नहीं देगी।
बहुभाषा विकसित करना एक स्थायी समाधान है भावना विश्लेषण प्रणाली जो सोशल मीडिया, मंचों, सर्वेक्षणों और अन्य में ग्राहकों की राय, भावनाओं और सुझावों का पता लगाता है और उनका विश्लेषण करता है।
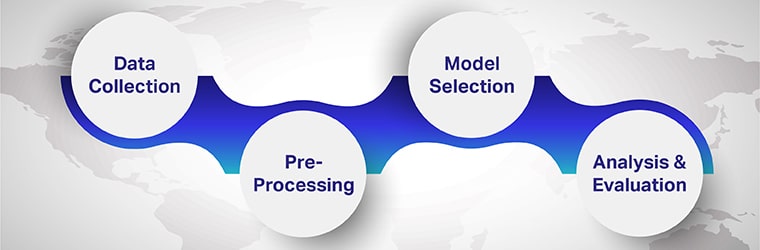
बहुभाषी मनोभाव विश्लेषण करने के चरण
भावना विश्लेषण, भले ही एक ही भाषा में हो या विभिन्न भाषाएं, एक ऐसी प्रक्रिया है जिसे निकालने के लिए मशीन लर्निंग मॉडल, प्राकृतिक भाषा प्रसंस्करण और डेटा विश्लेषण तकनीकों के अनुप्रयोग की आवश्यकता होती है बहुभाषी भावना स्कोरिंग डेटा से.
बहुभाषी भावना विश्लेषण में शामिल कदम हैं
चरण 1: डेटा एकत्र करना
भावना विश्लेषण को लागू करने के लिए डेटा एकत्र करना पहला कदम है। बहुभाषी बनाने के लिए भावना विश्लेषण मॉडल, विभिन्न भाषाओं में डेटा प्राप्त करना महत्वपूर्ण है। सब कुछ एकत्रित, एनोटेट और लेबल किए गए डेटा की गुणवत्ता पर निर्भर करेगा। आप एपीआई, ओपन-सोर्स रिपॉजिटरी और प्रकाशकों से डेटा प्राप्त कर सकते हैं।
चरण 2: प्री-प्रोसेसिंग
एकत्र किए गए वेब डेटा को साफ किया जाना चाहिए, और इससे जानकारी प्राप्त की जानी चाहिए। पाठ के वे हिस्से जो कोई विशेष अर्थ नहीं बताते हैं, जैसे कि 'द', 'है' और अधिक, को हटा दिया जाना चाहिए। इसके अलावा, पाठ को सकारात्मक या नकारात्मक अर्थ बताने के लिए वर्गीकृत किए जाने वाले शब्द समूहों में समूहीकृत किया जाना चाहिए।
वर्गीकरण की गुणवत्ता में सुधार करने के लिए, सामग्री को HTML टैग, विज्ञापन और स्क्रिप्ट जैसे शोर से मुक्त किया जाना चाहिए। लोगों द्वारा उपयोग की जाने वाली भाषा, शब्दकोष और व्याकरण सामाजिक नेटवर्क के आधार पर भिन्न होते हैं। ऐसी सामग्री को सामान्य बनाना और इसे पूर्व-प्रसंस्करण के लिए तैयार करना महत्वपूर्ण है।
पूर्व-प्रसंस्करण में एक और महत्वपूर्ण कदम प्राकृतिक भाषा प्रसंस्करण का उपयोग वाक्यों को विभाजित करने, स्टॉप शब्दों को हटाने, भाषण के हिस्सों को टैग करने, शब्दों को उनके मूल रूप में बदलने और शब्दों को प्रतीकों और पाठ में टोकन करने के लिए करना है।
चरण 3: मॉडल चयन
नियम-आधारित मॉडल: बहुभाषा सिमेंटिक विश्लेषण की सबसे सरल विधि नियम-आधारित है। नियम-आधारित एल्गोरिथ्म विशेषज्ञों द्वारा प्रोग्राम किए गए पूर्व निर्धारित नियमों के एक सेट के आधार पर विश्लेषण करता है।
नियम सकारात्मक या नकारात्मक शब्दों या वाक्यांशों को निर्दिष्ट कर सकता है। यदि आप किसी उत्पाद या सेवा की समीक्षा करते हैं, उदाहरण के लिए, इसमें सकारात्मक या नकारात्मक शब्द हो सकते हैं जैसे 'महान', 'धीमा', 'प्रतीक्षा करें' और 'उपयोगी'। यह विधि शब्दों को वर्गीकृत करना आसान बनाती है, लेकिन यह जटिल या कम बार-बार आने वाले शब्दों का गलत वर्गीकरण कर सकती है।
स्वचालित मॉडल: स्वचालित मॉडल मानव मध्यस्थों की भागीदारी के बिना बहुभाषी मनोभाव विश्लेषण करता है। यद्यपि मशीन लर्निंग मॉडल मानव प्रयास का उपयोग करके बनाया गया है, यह विकसित होने के बाद सटीक परिणाम देने के लिए स्वचालित रूप से काम कर सकता है।
टेस्ट डेटा का विश्लेषण किया जाता है, और प्रत्येक टिप्पणी को मैन्युअल रूप से सकारात्मक या नकारात्मक के रूप में लेबल किया जाता है। एमएल मॉडल तब नए पाठ की मौजूदा टिप्पणियों के साथ तुलना करके और उन्हें वर्गीकृत करके परीक्षण डेटा से सीखेगा।
चरण 4: विश्लेषण और मूल्यांकन
नियम-आधारित और मशीन-लर्निंग मॉडल को समय और अनुभव के साथ सुधारा और बढ़ाया जा सकता है। तेजी से और अधिक सटीक वर्गीकरण के लिए कम अक्सर इस्तेमाल किए जाने वाले शब्दों या बहुभाषी भावनाओं के लिए लाइव स्कोर का शब्दकोश अद्यतन किया जा सकता है।
अनुवाद की चुनौती
क्या अनुवाद काफी नहीं है? दरअसल नहीं!
अनुवाद में एक भाषा से पाठ या पाठ के समूहों को स्थानांतरित करना और दूसरी भाषा में समकक्ष खोजना शामिल है। हालाँकि, अनुवाद न तो सरल है और न ही प्रभावी।
ऐसा इसलिए है क्योंकि मनुष्य भाषा का उपयोग न केवल अपनी आवश्यकताओं को संप्रेषित करने के लिए करता है बल्कि अपनी भावनाओं को व्यक्त करने के लिए भी करता है। इसके अलावा, अंग्रेजी, हिंदी, मंदारिन और थाई जैसी विभिन्न भाषाओं के बीच काफी अंतर हैं। इस साहित्यिक मिश्रण में भावनाओं, कठबोली, मुहावरों, कटाक्ष और इमोजीस का उपयोग जोड़ें। पाठ का सटीक अनुवाद प्राप्त करना संभव नहीं है।
की कुछ मुख्य चुनौतियाँ मशीन अनुवाद रहे
- आत्मीयता
- संदर्भ
- कठबोली और मुहावरे
- ताना
- तुलना
- तटस्थता
- इमोजी और शब्दों का आधुनिक प्रयोग।
अपने उत्पादों, कीमतों, सेवाओं, सुविधाओं और गुणवत्ता के बारे में समीक्षाओं, टिप्पणियों और संचार के अभीष्ट अर्थ को सही ढंग से समझे बिना, व्यवसाय ग्राहकों की ज़रूरतों और विचारों को समझने में असमर्थ होंगे।
बहुभाषी भावना विश्लेषण एक चुनौतीपूर्ण प्रक्रिया है। प्रत्येक भाषा की अपनी अनूठी शब्दावली, वाक्य-विन्यास, आकृति विज्ञान और ध्वन्यात्मकता होती है। इसमें संस्कृति, कठबोली जोड़ें, भावनाओं को व्यक्त किया, कटाक्ष, और रागिनी, और आपके पास अपने लिए एक चुनौतीपूर्ण पहेली है जिसके लिए एक कुशल AI-संचालित ML समाधान की आवश्यकता है।
मजबूत बहुभाषी विकसित करने के लिए एक व्यापक बहु-भाषा डेटासेट की आवश्यकता है भावना विश्लेषण उपकरण जो समीक्षाओं को संसाधित कर सकता है और व्यवसायों को शक्तिशाली अंतर्दृष्टि प्रदान कर सकता है। Shaip कई भाषाओं में उद्योग-अनुकूलित, लेबल किए गए, एनोटेट किए गए डेटासेट प्रदान करने में मार्केट लीडर है जो कुशल और सटीक विकसित करने में सहायता करता है बहुभाषी भावना विश्लेषण समाधान.