
डेटा वह महाशक्ति है जो आज की दुनिया में डिजिटल परिदृश्य को बदल रही है। ईमेल से लेकर सोशल मीडिया पोस्ट तक हर जगह डेटा है। यह सच है कि व्यवसायों की इतनी अधिक डेटा तक पहुंच कभी नहीं रही है, लेकिन क्या डेटा तक पहुंच पर्याप्त है? सूचना का समृद्ध स्रोत बेकार या अप्रचलित हो जाता है जब इसे संसाधित नहीं किया जाता है।
असंरचित पाठ सूचना का एक समृद्ध स्रोत हो सकता है, लेकिन यह व्यवसायों के लिए तब तक उपयोगी नहीं होगा जब तक डेटा व्यवस्थित, वर्गीकृत और विश्लेषण नहीं किया जाता। असंरचित डेटा, जैसे पाठ, ऑडियो, वीडियो और सोशल मीडिया, की मात्रा 80 -90% सभी डेटा का। इसके अलावा, बमुश्किल 18% संगठन कथित तौर पर अपने संगठन के असंरचित डेटा का लाभ उठा रहे हैं।
सर्वर में संग्रहीत डेटा के टेराबाइट्स के माध्यम से मैन्युअल रूप से छानना एक समय लेने वाला और स्पष्ट रूप से असंभव कार्य है। हालांकि, मशीन लर्निंग, प्राकृतिक भाषा प्रसंस्करण और स्वचालन में प्रगति के साथ, पाठ डेटा को जल्दी और प्रभावी ढंग से संरचना और विश्लेषण करना संभव है। डेटा विश्लेषण में पहला कदम है पाठ वर्गीकरण.
पाठ वर्गीकरण क्या है?
पाठ वर्गीकरण या वर्गीकरण पाठ को पूर्व निर्धारित श्रेणियों या वर्गों में समूहीकृत करने की प्रक्रिया है। इस मशीन लर्निंग दृष्टिकोण का उपयोग करना, कोई भी पाठ - दस्तावेज़, वेब फ़ाइलें, अध्ययन, कानूनी दस्तावेज़, चिकित्सा रिपोर्ट, और बहुत कुछ - वर्गीकृत, संगठित और संरचित किया जा सकता है।
पाठ वर्गीकरण प्राकृतिक भाषा प्रसंस्करण में मूल चरण है जिसका स्पैम का पता लगाने में कई उपयोग हैं। भावना विश्लेषण, आशय का पता लगाने, डेटा लेबलिंग, और बहुत कुछ.
पाठ वर्गीकरण के संभावित उपयोग के मामले
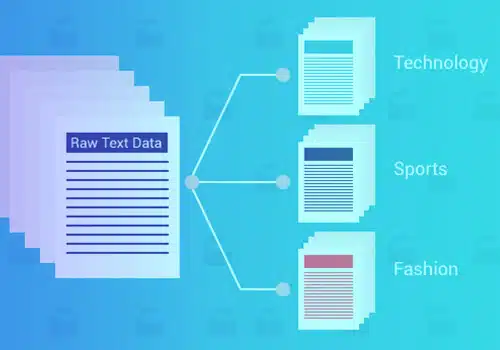 मशीन लर्निंग पाठ वर्गीकरण का उपयोग करने के कई लाभ हैं, जैसे मापनीयता, विश्लेषण की गति, निरंतरता और वास्तविक समय की बातचीत के आधार पर त्वरित निर्णय लेने की क्षमता।
मशीन लर्निंग पाठ वर्गीकरण का उपयोग करने के कई लाभ हैं, जैसे मापनीयता, विश्लेषण की गति, निरंतरता और वास्तविक समय की बातचीत के आधार पर त्वरित निर्णय लेने की क्षमता।
जब ML मॉडल को AI पर प्रशिक्षित किया जाता है जो स्वचालित रूप से प्री-सेट श्रेणियों के तहत आइटम को वर्गीकृत करता है, तो आप आकस्मिक ब्राउज़रों को जल्दी से ग्राहकों में बदल सकते हैं।
पाठ वर्गीकरण प्रक्रिया
पाठ वर्गीकरण प्रक्रिया पूर्व-प्रसंस्करण, सुविधा चयन, निष्कर्षण और वर्गीकरण डेटा के साथ शुरू होती है।

पूर्व प्रसंस्करण
tokenization: पाठ को आसान वर्गीकरण के लिए छोटे और सरल पाठ रूपों में विभाजित किया गया है।
सामान्यीकरण: दस्तावेज़ में सभी पाठ को समझने के समान स्तर पर होना चाहिए। सामान्यीकरण के कुछ रूपों में शामिल हैं,
- पूरे पाठ में व्याकरणिक या संरचनात्मक मानकों को बनाए रखना, जैसे सफेद रिक्त स्थान या विराम चिह्नों को हटाना। या पूरे टेक्स्ट में लोअर केस बनाए रखना।
- शब्दों में से उपसर्ग और प्रत्यय को हटाकर मूल शब्द में लाना।
- स्टॉप शब्द जैसे 'और' 'है' 'द' और अधिक को हटाना जो पाठ में मूल्य नहीं जोड़ते हैं।
फीचर चयन
फीचर चयन टेक्स्ट वर्गीकरण में एक मौलिक कदम है। प्रक्रिया का उद्देश्य सबसे प्रासंगिक विशेषता वाले ग्रंथों का प्रतिनिधित्व करना है। फ़ीचर चयन अप्रासंगिक डेटा को हटाने और सटीकता बढ़ाने में मदद करते हैं।
फ़ीचर चयन केवल सबसे अधिक प्रासंगिक डेटा का उपयोग करके और शोर को समाप्त करके मॉडल में इनपुट चर को कम करता है। आपके द्वारा खोजे जाने वाले समाधान के प्रकार के आधार पर, आपके AI मॉडल को पाठ से केवल प्रासंगिक सुविधाओं को चुनने के लिए डिज़ाइन किया जा सकता है।
सुविधा निकासी
सुविधा निष्कर्षण एक वैकल्पिक कदम है जिसे कुछ व्यवसाय डेटा में अतिरिक्त मुख्य विशेषताओं को निकालने के लिए करते हैं। फ़ीचर निष्कर्षण कई तकनीकों का उपयोग करता है, जैसे मैपिंग, फ़िल्टरिंग और क्लस्टरिंग। फीचर निष्कर्षण का उपयोग करने का प्राथमिक लाभ है - यह अनावश्यक डेटा को हटाने में मदद करता है और एमएल मॉडल के विकास की गति में सुधार करता है।
डेटा को पूर्वनिर्धारित श्रेणियों में टैग करना
पाठ को पूर्वनिर्धारित श्रेणियों में टैग करना पाठ वर्गीकरण का अंतिम चरण है। इसे तीन अलग-अलग तरीकों से किया जा सकता है,
- मैनुअल टैगिंग
- नियम-आधारित मिलान
- लर्निंग एल्गोरिदम - लर्निंग एल्गोरिदम को आगे दो श्रेणियों में वर्गीकृत किया जा सकता है जैसे सुपरवाइज्ड टैगिंग और अनसुपरवाइज्ड टैगिंग।
- पर्यवेक्षित शिक्षण: एमएल मॉडल स्वचालित रूप से पर्यवेक्षित टैगिंग में मौजूदा वर्गीकृत डेटा के साथ टैग को संरेखित कर सकता है। जब वर्गीकृत डेटा पहले से ही उपलब्ध होता है, एमएल एल्गोरिदम टैग और टेक्स्ट के बीच फ़ंक्शन को मैप कर सकता है।
- अनसुपरवाइज्ड लर्निंग: यह तब होता है जब पहले से मौजूद टैग किए गए डेटा की कमी होती है। एमएल मॉडल समान पाठों को समूहित करने के लिए क्लस्टरिंग और नियम-आधारित एल्गोरिदम का उपयोग करते हैं, जैसे उत्पाद खरीद इतिहास, समीक्षा, व्यक्तिगत विवरण और टिकट के आधार पर। मूल्यवान ग्राहक-विशिष्ट अंतर्दृष्टि प्राप्त करने के लिए इन व्यापक समूहों का और अधिक विश्लेषण किया जा सकता है, जिनका उपयोग अनुकूलित ग्राहक दृष्टिकोणों को डिजाइन करने के लिए किया जा सकता है।
उद्योगों में टेक्स्ट वर्गीकरण के लिए कई उपयोग मामले हैं। यद्यपि टेक्स्ट डेटा से मूल्यवान अंतर्दृष्टि एकत्र करना, समूह बनाना, वर्गीकृत करना और निकालना हमेशा कई क्षेत्रों में उपयोग किया गया है, टेक्स्ट वर्गीकरण विपणन, उत्पाद विकास, ग्राहक सेवा, प्रबंधन और प्रशासन में अपनी क्षमता खोज रहा है। यह व्यवसायों को प्रतिस्पर्धी बुद्धिमत्ता, बाजार और ग्राहक ज्ञान हासिल करने और डेटा-समर्थित व्यावसायिक निर्णय लेने में मदद कर रहा है।
एक प्रभावी और व्यावहारिक पाठ वर्गीकरण उपकरण विकसित करना आसान नहीं है। फिर भी, अपने डेटा-पार्टनर के रूप में शैप के साथ, आप एक प्रभावी, स्केलेबल और लागत प्रभावी एआई-आधारित पाठ वर्गीकरण उपकरण विकसित कर सकते हैं। हमारे पास टन है सटीक रूप से एनोटेट और रेडी-टू-यूज़ डेटासेट जिसे आपके मॉडल की अनूठी आवश्यकताओं के लिए अनुकूलित किया जा सकता है। हम आपके पाठ को प्रतिस्पर्धात्मक लाभ में बदलते हैं; आज ही संपर्क करें।


