एनएलपी प्रौद्योगिकी प्रगतिशील दर से प्रमुखता प्राप्त कर रही है। कंप्यूटर विज्ञान, सूचना इंजीनियरिंग और कृत्रिम बुद्धिमत्ता का संयोजन संभावित रूप से भाषा संबंधी बाधाओं को दूर कर सकता है। एनएलपी प्रौद्योगिकी के साथ, संचार के लिए उपयोग की जाने वाली भाषा से कोई फर्क नहीं पड़ता, सभी पक्ष उस भाषा में जानकारी सुन और पढ़ सकेंगे जिसे वे जानते हैं।
प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कंप्यूटर को मानव भाषाओं को समझने के लिए प्रशिक्षित करता है। यह लगातार सीखने और अधिक ज्ञान प्राप्त करने के लिए मशीन लर्निंग का उपयोग करता है। परिणामस्वरूप, एनएलपी-एआई संयोजन अधिक स्मार्ट होता जा रहा है। अपनी क्षमताओं का प्रयोग, जो उत्तरोत्तर बढ़ती ही जा रही है, अधिकाधिक दक्ष एवं उन्नत होती जायेगी।
प्राकृतिक भाषा प्रसंस्करण (एनएलपी) क्या है?
प्राकृतिक भाषा प्रसंस्करण कृत्रिम बुद्धिमत्ता की एक शाखा है जो भाषाविज्ञान को समझने और स्मार्ट कंप्यूटर प्रोग्राम बनाने के लिए अपनी शक्ति का उपयोग करती है। ये प्रोग्राम इंसानों की तरह टेक्स्ट और मौखिक संचार को समझने में सक्षम हैं। लेकिन एनएलपी तकनीक एक साथ कई भाषाओं को सीखने और समझने और उन्हें आपकी पसंद की भाषा में अनुवाद करने की क्षमता रखती है।
RSI एनएलपी तकनीक मशीन लर्निंग और डीप लर्निंग के साथ कम्प्यूटेशनल भाषाविज्ञान और भाषा के नियम-आधारित मॉडलिंग को जोड़ती है। इसके प्रयोग से कंप्यूटर टेक्स्ट या ऑडियो को समझकर ही उसे दूसरी भाषा में अनुवाद कर सकता है।
आज भी, हमारे पास क्रियाशील एनएलपी के कई उदाहरण हैं, जैसे सिरी, गूगल असिस्टेंट, गूगल ट्रांसलेटर, और कुछ ऑटो-सुझाव उपकरण। ईमेल लिखते समय या खोज इंजन में ग्रामरली द्वारा दिए गए सुझाव सभी एनएलपी तकनीक से सक्षम हैं।

एनएलपी टेक्नोलॉजी कैसे काम करती है?
एनएलपी तकनीक एक कंप्यूटर प्रोग्राम को मानव पाठ और भाषण को समझने में सक्षम बनाती है। चूँकि कंप्यूटर केवल 0 और 1 वाली बाइनरी भाषा को समझते हैं, इसलिए हमें पहले कंप्यूटर को शब्दों को समझाने के लिए एक प्रणाली की आवश्यकता थी।
इसके लिए, शब्द प्रतिनिधित्व का उपयोग किया जाता है, जहां शब्दों को कंप्यूटर भाषा में एन्कोड किया जाता है। इस उद्देश्य के लिए कई तकनीकों का उपयोग किया जाता है, और वन-हॉट इन तकनीकों में से एक है।
इसके अलावा, कंप्यूटर को मानव भाषा को समझने में मदद करने के लिए एनएलपी तकनीकों के एक सूट का उपयोग किया जाता है। इसमे शामिल है;
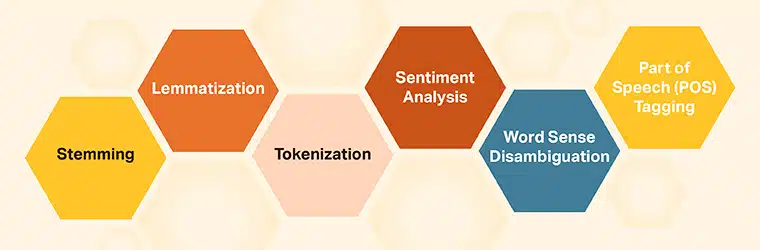
- स्टेमिंग: एक प्रक्रिया जहां समान शब्दों को उनके मूल शब्द से छोटा कर दिया जाता है, जैसे फ़ाइनलाइज़, फ़ाइनल से एक-एक करके अक्षर हटाकर।
- नींबू पानी: यह एक ऐसी तकनीक है जिससे शब्दों को उनकी सार्थक आधार संरचना खोजने के लिए मिटा दिया जाता है।
- tokenization: इस तकनीक के साथ, शब्दों, प्रतीकों और संख्याओं की पहचान करने के लिए वाक्यों को छोटे ब्लॉकों में तोड़ दिया जाता है।
- भावनाओं का विश्लेषण: यह वह जगह है जहां कंप्यूटर वाक्य के पीछे के स्वर और भावना को पहचानने का प्रयास करता है।
- शब्द बोध असंबद्धता: इस तकनीक का उपयोग यह निर्धारित करने के लिए किया जाता है कि क्या अलग-अलग संदर्भों में उपयोग किए जाने पर एक ही शब्द के अलग-अलग अर्थ होते हैं।
- भाषण का भाग (पीओएस) टैगिंग: पीओएस टैगिंग का उपयोग टेक्स्ट में प्रत्येक शब्द को एनोटेट करने के लिए किया जाता है। इसमें क्रिया, क्रियाविशेषण, संज्ञा, विशेषण और भाषण के अन्य सभी भागों की पहचान करना शामिल है।
इन तकनीकों के अलावा, एक एनएलपी कार्यक्रम मानव-जनित पाठ और भाषण को समझने के लिए एल्गोरिदम का भी उपयोग करता है। डेटा का विश्लेषण करने के लिए भाषाविज्ञान के नियम निर्धारित करने के लिए नियम-आधारित प्रणाली का उपयोग किया जाता है।
मशीन लर्निंग एनएलपी का एक महत्वपूर्ण हिस्सा है क्योंकि इसका उपयोग प्रशिक्षण डेटा को कंप्यूटर प्रोग्राम में जोड़ने के लिए किया जाता है। इस डेटा का उपयोग करके, एनएलपी प्रोग्राम अपने टेक्स्ट और ध्वनि पहचान पैटर्न को समायोजित कर सकता है।
[ये भी पढ़ें: आपको एनएलपी मॉडल प्रशिक्षित करने के लिए 15 सर्वश्रेष्ठ एनएलपी डेटासेट]
बिल्डिंग एनएलपी के लिए मशीनी अनुवाद

क्या आप कल्पना कर सकते हैं कि विश्व नेता उन बैठकों में कैसे भाग ले पाते हैं जहाँ हर कोई अपनी भाषा बोलता है? इन बैठकों में एक साथ व्याख्या प्रणाली होती है, जिसका अर्थ है कि कंप्यूटर प्रोग्राम और मानव दुभाषिए भाषण का अनुवाद करने के लिए एक साथ काम करते हैं और फिर आवश्यकतानुसार इसे अन्य भाषाओं में परिवर्तित करते हैं।
हालाँकि सभी भाषा बाधाओं को दूर करना एनएलपी तकनीक का वर्तमान अंतिम लक्ष्य हो सकता है, यह तकनीक अभी भी बढ़ रही है और आगे बढ़ रही है। एनएलपी तकनीक मशीन अनुवाद का उपयोग करके इसे संभव बनाती है, जो अनिवार्य रूप से पाठ और भाषण का अनुवाद करने के लिए एक कंप्यूटर प्रोग्राम का उपयोग करती है।
एक ऐसे चरण से आगे बढ़ते हुए जहां अशुद्धियाँ प्रमुख थीं, मशीनी अनुवाद ने देखा है न्यूरल मशीन ट्रांसलेशन (एनएमटी) के साथ सुधार. एनएमटी ने एनएलपी की कार्यप्रणाली में और सुधार किया है, जिससे इसकी अनुवाद क्षमताओं में सुधार हुआ है।
एनएलपी में मशीनी अनुवाद के लाभ इस प्रकार हैं:
- एनएलपी प्रोग्राम अब किताबों, वेबसाइटों और उत्पाद विवरणों को कुछ ही सेकंड में पढ़ और अनुवाद कर सकते हैं।
- इसने अनुवाद के लिए आवश्यक लागत और प्रयासों को काफी हद तक कम कर दिया है।
- मशीन लर्निंग एल्गोरिदम के उपयोग से सटीकता का स्तर भी बढ़ गया है।
- व्यवसाय अब अपनी आवश्यकताओं के अनुसार अनुवाद प्रक्रिया को अनुकूलित कर सकते हैं।
यह संभव है क्योंकि एनएमटी आवर्तक तंत्रिका नेटवर्क (आरएनएन) और ध्यान तंत्र जैसी गहन शिक्षण पद्धतियों का लाभ उठाता है। ये एनएलपी कार्यक्रम की क्षमताओं को बढ़ाते हैं, जिससे भाषाई नियमों, पैटर्न और लंबे वाक्यों और जटिल संरचनाओं वाले वाक्यों के लिए प्रसंस्करण गति की समझ की सीमा बढ़ जाती है।
एनएमटी एक प्रोग्राम को शब्दार्थ की दृष्टि से समान शब्दों को एक साथ रखकर, शब्दों को वेक्टर में बदलने में मदद करता है। वेक्टर या शब्दों का अनुक्रम उत्पन्न करके, प्रोग्राम एक वाक्य उत्पन्न करता है। यहां से, यह वेक्टर स्पेस में इनपुट वाक्य को मैप करने के लिए एनकोडर-डिकोडर ढांचे का उपयोग करता है, और डिकोडर अनुवादित वाक्य को इंटरफ़ेस पर भेजता है।
निष्कर्ष
एनएलपी, एनएमटी, तंत्रिका नेटवर्क और गहन शिक्षण तंत्र का संयोजन पाठ और वाक् पहचान और अनुवाद में महत्वपूर्ण सुधार ला रहा है। इस क्षेत्र में तमाम प्रगति के बावजूद, संतुलन बनाए रखने के लिए मानव दुभाषियों और संपादकों की आवश्यकता होती है। ऐसे व्यवसायों और कंपनियों के लिए जो अपनी स्वयं की व्याख्या प्रणाली चाहते हैं, एनएलपी और मशीनी अनुवाद से सुसज्जित संवादी एआई-आधारित बीस्पोक समाधानों के लिए शेप से संपर्क करें।