यदि आप सिरी, एलेक्सा, कोरटाना, अमेज़ॅन इको, या अन्य का उपयोग अपने दैनिक जीवन के हिस्से के रूप में करते हैं, तो आप इसे स्वीकार करेंगे वाक् पहचान हमारे जीवन का एक सर्वव्यापी हिस्सा बन गया है। इन कृत्रिम बुद्धि संचालित ध्वनि सहायक उपयोगकर्ताओं के मौखिक प्रश्नों को पाठ में परिवर्तित करते हैं, व्याख्या करते हैं और समझते हैं कि उपयोगकर्ता उचित प्रतिक्रिया के साथ आने के लिए क्या कह रहा है।
विश्वसनीय भाषण, मान्यता मॉडल विकसित करने के लिए गुणवत्तापूर्ण डेटा संग्रह की आवश्यकता है। लेकिन, विकासशील वाक् पहचान सॉफ्टवेयर एक आसान काम नहीं है - ठीक है क्योंकि मानव भाषण को उसकी सभी जटिलताओं, जैसे लय, उच्चारण, पिच और स्पष्टता में लिप्यंतरित करना मुश्किल है। और, जब आप इस जटिल मिश्रण में भावनाओं को जोड़ते हैं, तो यह एक चुनौती बन जाती है।
वाक् पहचान क्या है?
वाक् पहचान सॉफ्टवेयर की पहचानने और प्रक्रिया करने की क्षमता है मानव भाषण पाठ में। जबकि आवाज की पहचान और भाषण की पहचान के बीच का अंतर कई लोगों के लिए व्यक्तिपरक लग सकता है, दोनों के बीच कुछ मूलभूत अंतर हैं।
यद्यपि भाषण और आवाज पहचान दोनों ही आवाज सहायक तकनीक का एक हिस्सा हैं, वे दो अलग-अलग कार्य करते हैं। भाषण मान्यता मानव भाषण और पाठ में आदेशों के स्वचालित प्रतिलेखन करती है, जबकि आवाज पहचान केवल वक्ता की आवाज को पहचानने से संबंधित है।
भाषण मान्यता के प्रकार
इससे पहले कि हम कूदें वाक् पहचान प्रकार, आइए वाक् पहचान डेटा पर एक संक्षिप्त नज़र डालें।
स्पीच रिकग्निशन डेटा मानव भाषण ऑडियो रिकॉर्डिंग और टेक्स्ट ट्रांसक्रिप्शन का एक संग्रह है जो मशीन लर्निंग सिस्टम को प्रशिक्षित करने में मदद करता है आवाज मान्यता.
ऑडियो रिकॉर्डिंग और ट्रांसक्रिप्शन एमएल सिस्टम में दर्ज किए जाते हैं ताकि एल्गोरिदम को भाषण की बारीकियों को पहचानने और इसके अर्थ को समझने के लिए प्रशिक्षित किया जा सके।
हालांकि ऐसे कई स्थान हैं जहां आप मुफ्त प्री-पैकेज्ड डेटासेट प्राप्त कर सकते हैं, इसे प्राप्त करना सबसे अच्छा है अनुकूलित डेटासेट आपकी परियोजनाओं के लिए। आप कस्टम डेटासेट के द्वारा संग्रह आकार, ऑडियो और स्पीकर आवश्यकताओं और भाषा का चयन कर सकते हैं।
भाषण डेटा स्पेक्ट्रम
भाषण डेटा स्पेक्ट्रम प्राकृतिक से अप्राकृतिक तक भाषण की गुणवत्ता और पिच की पहचान करता है।
स्क्रिप्टेड वाक् पहचान डेटा
जैसा कि नाम से पता चलता है, स्क्रिप्टेड स्पीच डेटा का एक नियंत्रित रूप है। वक्ता तैयार पाठ से विशिष्ट वाक्यांशों को रिकॉर्ड करते हैं। ये आम तौर पर आदेश देने के लिए उपयोग किए जाते हैं, इस बात पर बल देते हैं कि कैसे शब्द या वाक्यांश जो कहा जा रहा है उसके बजाय कहा जाता है।
स्क्रिप्टेड स्पीच रिकग्निशन का उपयोग वॉयस असिस्टेंट विकसित करते समय किया जा सकता है जो विभिन्न स्पीकर एक्सेंट का उपयोग करके जारी किए गए कमांड को उठाएगा।
परिदृश्य-आधारित वाक् पहचान
परिदृश्य-आधारित भाषण में, वक्ता को एक विशेष परिदृश्य की कल्पना करने और जारी करने के लिए कहा जाता है आवाज आज्ञा परिदृश्य के आधार पर। इस तरह, परिणाम वॉयस कमांड का एक संग्रह है जो स्क्रिप्टेड नहीं है बल्कि नियंत्रित है।
परिदृश्य-आधारित वाक् डेटा की आवश्यकता उन डेवलपर्स को होती है जो एक ऐसा उपकरण विकसित करना चाहते हैं जो रोज़मर्रा के भाषण को उसकी विभिन्न बारीकियों के साथ समझता हो। उदाहरण के लिए, विभिन्न प्रकार के प्रश्नों का उपयोग करके निकटतम पिज़्ज़ा हट पर जाने के लिए दिशा-निर्देश मांगना।
प्राकृतिक भाषण मान्यता
भाषण स्पेक्ट्रम के ठीक अंत में वह भाषण होता है जो सहज, स्वाभाविक और किसी भी तरह से नियंत्रित नहीं होता है। वक्ता अपने स्वाभाविक संवादात्मक स्वर, भाषा, पिच और स्वर का उपयोग करके स्वतंत्र रूप से बोलता है।
यदि आप मल्टी-स्पीकर स्पीच रिकग्निशन पर एमएल-आधारित एप्लिकेशन को प्रशिक्षित करना चाहते हैं, तो एक अनस्क्रिप्टेड या संवादी भाषण डेटासेट उपयोगी है।
भाषण परियोजनाओं के लिए डेटा संग्रह घटक
 भाषण डेटा संग्रह में शामिल चरणों की एक श्रृंखला यह सुनिश्चित करती है कि एकत्र किया गया डेटा गुणवत्ता वाला है और उच्च गुणवत्ता वाले एआई-आधारित मॉडल को प्रशिक्षित करने में मदद करता है।
भाषण डेटा संग्रह में शामिल चरणों की एक श्रृंखला यह सुनिश्चित करती है कि एकत्र किया गया डेटा गुणवत्ता वाला है और उच्च गुणवत्ता वाले एआई-आधारित मॉडल को प्रशिक्षित करने में मदद करता है।
आवश्यक उपयोगकर्ता प्रतिक्रियाओं को समझें
मॉडल के लिए आवश्यक उपयोगकर्ता प्रतिक्रियाओं को समझकर प्रारंभ करें। वाक् पहचान मॉडल विकसित करने के लिए, आपको ऐसा डेटा एकत्र करना चाहिए जो आपके लिए आवश्यक सामग्री का बारीकी से प्रतिनिधित्व करता हो। उपयोगकर्ता की बातचीत और प्रतिक्रियाओं को समझने के लिए वास्तविक दुनिया की बातचीत से डेटा इकट्ठा करें। यदि आप एआई-आधारित चैट सहायक बना रहे हैं, तो डेटासेट बनाने के लिए चैट लॉग्स, कॉल रिकॉर्डिंग्स, चैट डायलॉग बॉक्स प्रतिक्रियाओं को देखें।
डोमेन-विशिष्ट भाषा की जांच करें
वाक् पहचान डेटासेट के लिए आपको सामान्य और डोमेन-विशिष्ट सामग्री दोनों की आवश्यकता होती है। एक बार जब आप सामान्य भाषण डेटा एकत्र कर लेते हैं, तो आपको डेटा की छानबीन करनी चाहिए और सामान्य को विशिष्ट से अलग करना चाहिए।
उदाहरण के लिए, ग्राहक किसी नेत्र देखभाल केंद्र में ग्लूकोमा की जांच के लिए मिलने का समय मांगने के लिए कॉल कर सकते हैं। अपॉइंटमेंट के लिए पूछना एक अत्यधिक सामान्य शब्द है, लेकिन ग्लूकोमा डोमेन-विशिष्ट है।
इसके अलावा, भाषण पहचान एमएल मॉडल का प्रशिक्षण लेते समय, सुनिश्चित करें कि आप इसे अलग-अलग के बजाय वाक्यांशों की पहचान करने के लिए प्रशिक्षित करते हैं मान्यता प्राप्त शब्द.
रिकॉर्ड मानव भाषण
पिछले दो चरणों से डेटा एकत्र करने के बाद, अगले चरण में मानवों को एकत्र किए गए बयानों को दर्ज करना शामिल होगा।
स्क्रिप्ट की एक आदर्श लंबाई बनाए रखना आवश्यक है। लोगों से 15 मिनट से अधिक पाठ पढ़ने के लिए कहना प्रतिकूल हो सकता है। दर्ज किए गए प्रत्येक बयान के बीच कम से कम 2-3 सेकंड का अंतर रखें।
रिकॉर्डिंग को गतिशील होने दें
अलग-अलग लोगों, बोलने के लहज़े, अलग-अलग परिस्थितियों में रिकॉर्ड की गई शैलियों, उपकरणों और परिवेशों का एक भाषण भंडार बनाएँ। यदि भविष्य के अधिकांश उपयोगकर्ता लैंडलाइन का उपयोग करने जा रहे हैं, तो आपके भाषण संग्रह डेटाबेस में एक महत्वपूर्ण प्रतिनिधित्व होना चाहिए जो उस आवश्यकता से मेल खाता हो।

भाषण रिकॉर्डिंग में परिवर्तनशीलता को प्रेरित करें
एक बार लक्ष्य वातावरण स्थापित हो जाने के बाद, अपने डेटा संग्रह विषयों को समान वातावरण के तहत तैयार स्क्रिप्ट को पढ़ने के लिए कहें। विषयों को गलतियों के बारे में चिंता न करने और जितना संभव हो उतना स्वाभाविक रूप से प्रस्तुत करने के लिए कहें। विचार यह है कि लोगों का एक बड़ा समूह एक ही वातावरण में स्क्रिप्ट रिकॉर्ड कर रहा हो।
भाषणों का लिप्यंतरण करें
एक बार जब आप कई विषयों (गलतियों के साथ) का उपयोग करके स्क्रिप्ट रिकॉर्ड कर लेते हैं, तो आपको ट्रांसक्रिप्शन के साथ आगे बढ़ना चाहिए। गलतियों को बरकरार रखें, क्योंकि इससे आपको एकत्रित आंकड़ों में गतिशीलता और विविधता हासिल करने में मदद मिलेगी।
मनुष्यों द्वारा पूरे पाठ शब्द को शब्दशः लिप्यंतरित करने के बजाय, आप प्रतिलेखन करने के लिए वाक्-से-पाठ इंजन शामिल कर सकते हैं। हालाँकि, हम यह भी सुझाव देते हैं कि आप गलतियों को सुधारने के लिए मानव प्रतिलेखकों को नियुक्त करें।
एक परीक्षण सेट विकसित करें
एक परीक्षण सेट विकसित करना महत्वपूर्ण है क्योंकि यह सबसे आगे चलने वाला है भाषा मॉडल.
भाषण और संबंधित पाठ की जोड़ी बनाएं और उन्हें खंडों में बनाएं।
एकत्रित तत्वों को इकट्ठा करने के बाद, 20% का नमूना निकालें, जो परीक्षण सेट बनाता है। यह प्रशिक्षण सेट नहीं है, लेकिन यह निकाला गया डेटा आपको बताएगा कि क्या प्रशिक्षित मॉडल ऑडियो को ट्रांसक्राइब करता है जिस पर उसे प्रशिक्षित नहीं किया गया है।
भाषा प्रशिक्षण मॉडल बनाएं और मापें
अब डोमेन-विशिष्ट कथनों और यदि आवश्यक हो तो अतिरिक्त विविधताओं का उपयोग करके वाक् पहचान भाषा मॉडल बनाएं। एक बार जब आप मॉडल को प्रशिक्षित कर लेते हैं, तो आपको इसे मापना शुरू कर देना चाहिए।
प्रशिक्षण मॉडल (80% चयनित ऑडियो सेगमेंट के साथ) लें और भविष्यवाणियों और विश्वसनीयता की जांच के लिए परीक्षण सेट (निकाले गए 20% डेटासेट) के खिलाफ इसका परीक्षण करें। गलतियों, पैटर्न की जाँच करें और पर्यावरणीय कारकों पर ध्यान केंद्रित करें जिन्हें ठीक किया जा सकता है।
संभावित उपयोग के मामले या अनुप्रयोग
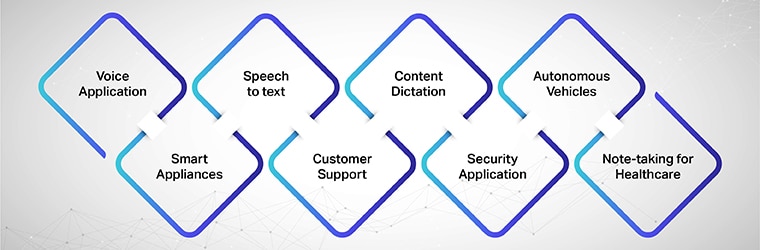
वॉयस एप्लिकेशन, स्मार्ट उपकरण, भाषण से टेक्स्ट, ग्राहक सहायता, सामग्री डिक्टेशन, सुरक्षा एप्लिकेशन, स्वायत्त वाहन, स्वास्थ्य देखभाल के लिए नोट लेना।
वाक् पहचान संभावनाओं की दुनिया खोलती है, और पिछले कुछ वर्षों में ध्वनि अनुप्रयोगों को अपनाने वाले उपयोगकर्ताओं में वृद्धि हुई है।
के कुछ सामान्य अनुप्रयोग वाक् पहचान प्रौद्योगिकी शामिल हैं:
ध्वनि खोज अनुप्रयोग
Google के अनुसार, 20% के बारे में Google ऐप पर की गई कुल खोजें वॉइस हैं। आठ अरब लोग 2023 तक वॉयस असिस्टेंट का उपयोग करने का अनुमान है, 6.4 में अनुमानित 2022 बिलियन से तेज वृद्धि।
वॉयस सर्च अपनाने में पिछले कुछ वर्षों में काफी वृद्धि हुई है, और इस प्रवृत्ति के जारी रहने की भविष्यवाणी की गई है। उपभोक्ता प्रश्नों को खोजने, उत्पादों को खरीदने, व्यवसायों का पता लगाने, स्थानीय व्यवसायों को खोजने आदि के लिए ध्वनि खोज पर भरोसा करते हैं।
घरेलू उपकरण/स्मार्ट उपकरण
घरेलू स्मार्ट उपकरणों जैसे टीवी, लाइट और अन्य उपकरणों को वॉयस कमांड प्रदान करने के लिए वॉयस रिकग्निशन तकनीक का उपयोग किया जा रहा है। उपभोक्ताओं के 66% यूके, यूएस और जर्मनी में कहा गया है कि वे स्मार्ट डिवाइस और स्पीकर का उपयोग करते समय ध्वनि सहायकों का उपयोग करते हैं।
पाठ को भाषण
ईमेल, दस्तावेज़, रिपोर्ट और अन्य टाइप करते समय मुफ्त कंप्यूटिंग में सहायता के लिए स्पीच-टू-टेक्स्ट एप्लिकेशन का उपयोग किया जा रहा है। पाठ को भाषण दस्तावेजों को टाइप करने, किताबें और मेल लिखने, वीडियो उपशीर्षक देने और पाठ का अनुवाद करने का समय समाप्त कर देता है।
ग्राहक सहयोग
वाक् पहचान अनुप्रयोगों का उपयोग मुख्य रूप से ग्राहक सेवा और सहायता में किया जाता है। भाषण पहचान प्रणाली सीमित संख्या में प्रतिनिधियों के साथ सस्ती कीमत पर 24/7 ग्राहक सेवा समाधान प्रदान करने में मदद करती है।
सामग्री डिक्टेशन
सामग्री श्रुतलेख एक और है वाक् पहचान उपयोग मामला जो छात्रों और शिक्षाविदों को कम समय में व्यापक सामग्री लिखने में मदद करता है। अंधेपन या दृष्टि की समस्याओं के कारण नुकसान में रहने वाले छात्रों के लिए यह काफी मददगार है।
सुरक्षा आवेदन
अद्वितीय आवाज विशेषताओं की पहचान करके सुरक्षा और प्रमाणीकरण उद्देश्यों के लिए आवाज पहचान का व्यापक रूप से उपयोग किया जाता है। चोरी या दुरुपयोग की गई व्यक्तिगत जानकारी का उपयोग करके व्यक्ति को अपनी पहचान कराने के बजाय, वॉयस बायोमेट्रिक्स सुरक्षा बढ़ाता है।
इसके अलावा, सुरक्षा उद्देश्यों के लिए आवाज की पहचान ने ग्राहकों की संतुष्टि के स्तर में सुधार किया है क्योंकि यह विस्तारित लॉगिन प्रक्रिया और क्रेडेंशियल डुप्लिकेशन को दूर करता है।
वाहनों के लिए वॉयस कमांड
ड्राइविंग सुरक्षा को बढ़ाने के लिए वाहनों, मुख्य रूप से कारों में अब एक आम आवाज पहचान सुविधा है। यह ड्राइवरों को रेडियो स्टेशनों का चयन करने, कॉल करने या वॉल्यूम कम करने जैसे सरल वॉयस कमांड को स्वीकार करके ड्राइविंग पर ध्यान केंद्रित करने में मदद करता है।
स्वास्थ्य देखभाल के लिए नोटबंदी
स्पीच रिकग्निशन एल्गोरिदम का उपयोग करके बनाया गया मेडिकल ट्रांसक्रिप्शन सॉफ्टवेयर डॉक्टरों के वॉयस नोट्स, कमांड, डायग्नोसिस और लक्षणों को आसानी से पकड़ लेता है। मेडिकल नोट लेने से स्वास्थ्य सेवा उद्योग में गुणवत्ता और तात्कालिकता बढ़ जाती है।
क्या आपके मन में वाक् पहचान परियोजना है जो आपके व्यवसाय को बदल सकती है? आपको केवल एक अनुकूलित वाक् पहचान डेटासेट की आवश्यकता हो सकती है।
सिंटैक्स, व्याकरण, वाक्य संरचना, भावनाओं और मानव भाषण की बारीकियों को एकीकृत करने के लिए एआई-आधारित वाक् पहचान सॉफ़्टवेयर को मशीन लर्निंग एल्गोरिदम पर विश्वसनीय डेटासेट पर प्रशिक्षित करने की आवश्यकता है। सबसे महत्वपूर्ण बात यह है कि सॉफ्टवेयर को लगातार सीखना और जवाब देना चाहिए - हर बातचीत के साथ बढ़ना चाहिए।
शैप में, हम विभिन्न मशीन लर्निंग प्रोजेक्ट्स के लिए पूरी तरह से अनुकूलित वाक् पहचान डेटासेट प्रदान करते हैं। शैप के साथ, आपकी पहुंच है उच्चतम गुणवत्ता दर्जी प्रशिक्षण डेटा जिसका उपयोग विश्वसनीय वाक् पहचान प्रणाली के निर्माण और विपणन के लिए किया जा सकता है। हमारी पेशकशों को व्यापक रूप से समझने के लिए हमारे विशेषज्ञों से संपर्क करें।
[ये भी पढ़ें: संवादी एआई के लिए पूरी गाइड]