
मशीन लर्निंग में टेक्स्ट एनोटेशन क्या है?
मशीन लर्निंग में टेक्स्ट एनोटेशन का तात्पर्य मशीन लर्निंग मॉडल के प्रशिक्षण, मूल्यांकन और सुधार के लिए संरचित डेटासेट बनाने के लिए कच्चे टेक्स्ट डेटा में मेटाडेटा या लेबल जोड़ने से है। यह प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कार्यों में एक महत्वपूर्ण कदम है, क्योंकि यह एल्गोरिदम को पाठ्य इनपुट के आधार पर समझने, व्याख्या करने और भविष्यवाणियां करने में मदद करता है।
टेक्स्ट एनोटेशन महत्वपूर्ण है क्योंकि यह असंरचित टेक्स्ट डेटा और संरचित, मशीन-पठनीय डेटा के बीच अंतर को पाटने में मदद करता है। यह मशीन लर्निंग मॉडल को एनोटेट किए गए उदाहरणों से पैटर्न सीखने और सामान्यीकृत करने में सक्षम बनाता है।
सटीक और मजबूत मॉडल बनाने के लिए उच्च-गुणवत्ता वाले एनोटेशन महत्वपूर्ण हैं। यही कारण है कि टेक्स्ट एनोटेशन में विवरण, स्थिरता और डोमेन विशेषज्ञता पर सावधानीपूर्वक ध्यान देना आवश्यक है।
टेक्स्ट एनोटेशन के प्रकार

एनएलपी एल्गोरिदम को प्रशिक्षित करते समय, प्रत्येक प्रोजेक्ट की विशिष्ट आवश्यकताओं के अनुरूप बड़े एनोटेटेड टेक्स्ट डेटासेट का होना आवश्यक है। इसलिए, उन डेवलपर्स के लिए जो ऐसे डेटासेट बनाना चाहते हैं, यहां पांच लोकप्रिय टेक्स्ट एनोटेशन प्रकारों का एक सरल अवलोकन दिया गया है।

सेंटीमेंट एनोटेशन
सेंटिमेंट एनोटेशन किसी पाठ की अंतर्निहित भावनाओं, राय या दृष्टिकोण की पहचान करता है। एनोटेटर पाठ्य खंडों को सकारात्मक, नकारात्मक या तटस्थ भावना टैग के साथ लेबल करते हैं। भावना विश्लेषण, इस एनोटेशन प्रकार का एक प्रमुख अनुप्रयोग, सोशल मीडिया निगरानी, ग्राहक प्रतिक्रिया विश्लेषण और बाजार अनुसंधान में व्यापक रूप से उपयोग किया जाता है।
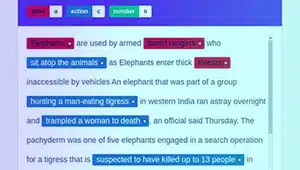
आशय व्याख्या
आशय एनोटेशन का उद्देश्य किसी दिए गए पाठ के पीछे के उद्देश्य या लक्ष्य को पकड़ना है। इस प्रकार के एनोटेशन में, एनोटेटर विशिष्ट उपयोगकर्ता इरादों का प्रतिनिधित्व करने वाले टेक्स्ट सेगमेंट को लेबल निर्दिष्ट करते हैं, जैसे जानकारी मांगना, कुछ अनुरोध करना, या प्राथमिकता व्यक्त करना।
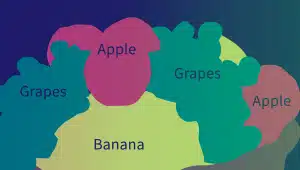
शब्दार्थ एनोटेशन
सिमेंटिक एनोटेशन शब्दों, वाक्यांशों और वाक्यों के बीच अर्थ और संबंधों की पहचान करता है। एनोटेटर पाठ तत्वों के अर्थ संबंधी गुणों को लेबल और वर्गीकृत करने के लिए विभिन्न तकनीकों, जैसे पाठ विभाजन, दस्तावेज़ विश्लेषण और पाठ निष्कर्षण का उपयोग करते हैं।

इकाई एनोटेशन
चैटबॉट प्रशिक्षण डेटासेट और अन्य एनएलपी डेटा बनाने में इकाई एनोटेशन महत्वपूर्ण है। इसमें पाठ में इकाइयों को ढूंढना और लेबल करना शामिल है। इकाई एनोटेशन के प्रकारों में शामिल हैं:

भाषाई व्याख्या
भाषाई व्याख्या भाषा के संरचनात्मक और व्याकरणिक पहलुओं से संबंधित है। इसमें विभिन्न उप-कार्य शामिल हैं, जैसे कि पार्ट-ऑफ़-स्पीच टैगिंग, सिंटेक्टिक पार्सिंग और रूपात्मक विश्लेषण।

बीमा
टेक्स्ट एनोटेशन बीमा कंपनियों को ग्राहकों की प्रतिक्रिया का विश्लेषण करने, दावों को संसाधित करने और धोखाधड़ी का पता लगाने में मदद करता है। एनोटेटेड डेटासेट पर प्रशिक्षित एआई मॉडल का उपयोग करके, बीमाकर्ता यह कर सकते हैं:

बैंकिंग
टेक्स्ट एनोटेशन बैंकिंग में बेहतर ग्राहक सेवा, धोखाधड़ी का पता लगाने और दस्तावेज़ विश्लेषण की सुविधा प्रदान करता है। एनोटेटेड डेटा पर प्रशिक्षित एआई सिस्टम:

दूरसंचार
टेक्स्ट एनोटेशन दूरसंचार कंपनियों को ग्राहक सहायता बढ़ाने, सोशल मीडिया की निगरानी करने और नेटवर्क समस्याओं का प्रबंधन करने में सक्षम बनाता है। एनोटेटेड डेटासेट पर प्रशिक्षित मशीन लर्निंग मॉडल:
टेक्स्ट डेटा को एनोटेट कैसे करें?
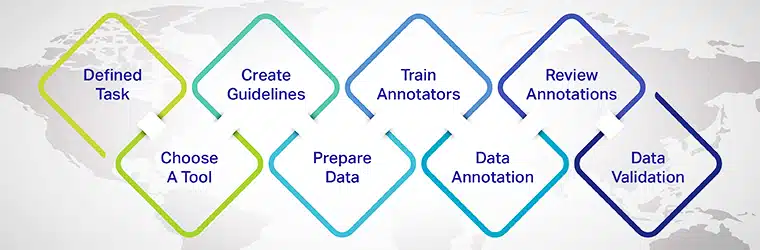
- एनोटेशन कार्य को परिभाषित करें: उस विशिष्ट एनएलपी कार्य को निर्धारित करें जिसे आप संबोधित करना चाहते हैं, जैसे भावना विश्लेषण, नामित इकाई पहचान, या पाठ वर्गीकरण।
- एक उपयुक्त एनोटेशन टूल चुनें: एक टेक्स्ट एनोटेशन टूल या प्लेटफ़ॉर्म चुनें जो आपके प्रोजेक्ट की आवश्यकताओं को पूरा करता हो और वांछित एनोटेशन प्रकारों का समर्थन करता हो।
- एनोटेशन दिशानिर्देश बनाएं: उच्च-गुणवत्ता और सटीक एनोटेशन सुनिश्चित करते हुए एनोटेटर्स के पालन के लिए स्पष्ट और सुसंगत दिशानिर्देश विकसित करें।
- डेटा चुनें और तैयार करें: एनोटेटर्स के काम करने के लिए कच्चे पाठ डेटा का एक विविध और प्रतिनिधि नमूना इकट्ठा करें।
- व्याख्याकारों को प्रशिक्षित करें और उनका मूल्यांकन करें: एनोटेशन प्रक्रिया में निरंतरता और गुणवत्ता सुनिश्चित करते हुए एनोटेटर्स को प्रशिक्षण और निरंतर फीडबैक प्रदान करें।
- डेटा को एनोटेट करें: एनोटेटर परिभाषित दिशानिर्देशों और एनोटेशन प्रकारों के अनुसार पाठ को लेबल करते हैं।
- एनोटेशन की समीक्षा करें और उसे परिष्कृत करें: नियमित रूप से एनोटेशन की समीक्षा करें और उसे परिष्कृत करें, किसी भी विसंगति या त्रुटि को संबोधित करें और डेटासेट में पुनरावृत्तीय रूप से सुधार करें।
- डेटासेट विभाजित करें: मशीन लर्निंग मॉडल को प्रशिक्षित और मूल्यांकन करने के लिए एनोटेट किए गए डेटा को प्रशिक्षण, सत्यापन और परीक्षण सेट में विभाजित करें।
शेप आपके लिए क्या कर सकता है?
शेप सिलवाया ऑफर पाठ एनोटेशन समाधान विभिन्न उद्योगों में आपके एआई और मशीन लर्निंग अनुप्रयोगों को सशक्त बनाने के लिए। उच्च-गुणवत्ता और सटीक एनोटेशन पर मजबूत फोकस के साथ, शेप की अनुभवी टीम और उन्नत एनोटेशन प्लेटफ़ॉर्म विविध टेक्स्ट डेटा को संभाल सकते हैं।
चाहे वह भावना विश्लेषण हो, नामित इकाई पहचान हो, या पाठ वर्गीकरण हो, शेप आपके एआई मॉडल की भाषा समझ और प्रदर्शन को बढ़ाने में मदद करने के लिए कस्टम डेटासेट प्रदान करता है।
अपनी टेक्स्ट एनोटेशन प्रक्रिया को सुव्यवस्थित करने और यह सुनिश्चित करने के लिए शेप पर भरोसा करें कि आपके एआई सिस्टम अपनी पूरी क्षमता तक पहुंचें।

